
这是一个创建于 1235 天前的主题,其中的信息可能已经有所发展或是发生改变。
有点看不懂下面的第一段语句。
SELECT 后面不是接一个 output 吗?为什么可以在里面再写一个 SELECT ?
SELECT (SELECT S.name FROM student AS S
WHERE S.sid = E.sid) AS sname
FROM enrolled as E
WHERE cid='15-455'
第二段语句和第一段语句的效果是一样的,但是第二段就很好理解。把第二个 SELECT 的 output 作为 input 传递给 IN 函数。
SELECT name FROM student
WHERE sid IN (
SELECT sid FROM enrolled
WHERE cid = '15-445'
)
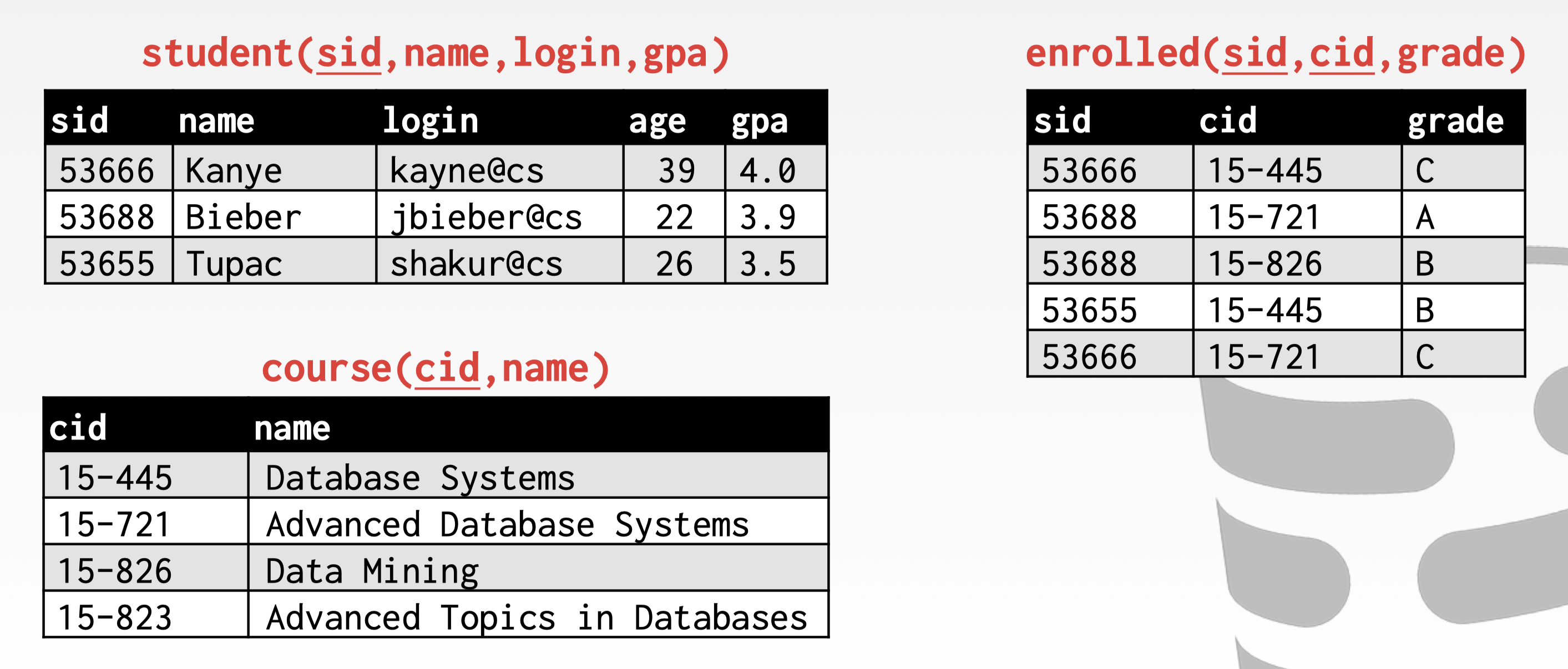
这里面是原始表格:
 |
1
akira 2021-07-12 21:47:32 +08:00
SELECT 后面不是接一个 output 吗?为什么可以在里面再写一个 SELECT ?
把第二个 SELECT 的 output 作为 input 传递给 IN 函数。 你自己的这 2 句话,再琢磨琢磨? |
 |
2
xcstream 2021-07-12 22:04:30 +08:00
结果可以作为一个表
|
 |
3
WalkerCeng 2021-07-12 22:05:56 +08:00
建议复习一下 MySQL
|
 |
4
movq OP @akira 你的意思是第一个 query 里面,括号包着的那个部分,作为一个 output,传递给括号外面的 SELECT 吗?
|
|
5
movq OP @WalkerCeng 正在从 0 开始学
|
 |
6
JamesMackerel 2021-07-13 00:55:16 +08:00 via iPhone
关键字:子查询
|
 |
7
Rocketer 2021-07-13 01:08:35 +08:00 via iPhone
各个部分皆可子查询,只要输出的结果符合那个部分的格式即可
|
 |
8
xiangyuecn 2021-07-13 09:00:31 +08:00
select (select count(...) from A ...) from B ... 这种写法 我这用的非常多 简直到了出神入化的境界🐶😂 通用性极强 基本上无法用其他写法来改写 否则要么看不懂要么性能极低
|
 |
9
l0ve1o24 2021-07-13 09:07:44 +08:00
@xiangyuecn 可以用外连接,然后 sum(case when A.id is not null then 1 else 0) ,我记得这样好像速度会快一点
|
 |
10
css3 2021-07-13 09:12:27 +08:00 发帖格式点赞,楼主需要看下 sql 最基础的语法
|
 |
11
dk7952638 2021-07-13 09:18:22 +08:00 @xiangyuecn 这种写法可读性差,但性能真的比 join 要高很多
|
 |
12
qwer666df 2021-07-13 09:18:22 +08:00
子查询的基操, 好几种变换格式, 贴个链接: https://www.cnblogs.com/CL-King/p/13730529.html
|
 |
13
aguesuka 2021-07-13 09:24:35 +08:00
https://docs.oracle.com/cd/E11882_01/server.112/e41084/expressions013.htm#SQLRF52093
Scalar Subquery Expressions 这是为什么 SQL 没有静态安全的万恶之源之一 |
|
14
xiangyuecn 2021-07-13 09:42:23 +08:00
|
 |
15
onionKnight888 2021-07-13 10:11:52 +08:00
我们业务系统如果用 oracle 的话,基本上都是这种子查询
|
 |
16
chanchan 2021-07-13 10:27:41 +08:00
垃圾 DSL 确实恶心
|
 |
17
aliveyang 2021-07-13 11:09:20 +08:00
你把他看作程序一步一步执行就行了,只要格式输出符合,怎么玩都可以
|
 |
18
sytnishizuiai 2021-07-13 11:35:54 +08:00
这种可以写的,而且有时候情况复杂的时候还不得不这么写。
不过你的问题描述的仔细,格式真不错,我之前提问,描述的没你直观。 |
 |
19
hanssx 2021-07-13 11:39:35 +08:00
确实有点反直觉,第 1 个是相关子查询,第 2 个是不相关子查询,如果相关子查询没优化的情况下,效率应该比不相关子查询低?
|
 |
20
way2explore2 2021-07-13 11:50:25 +08:00
SUBQuery liao jie yi xia
|
 |
21
yolee599 2021-07-13 12:37:57 +08:00 via Android
这叫子查询,基本操作
|
 |
22
huigeer 2021-07-13 12:39:06 +08:00
万物皆可子查询
|
 |
23
levon 2021-07-13 15:44:38 +08:00
order by (select ....)
|
 |
24
landfill 2021-07-13 16:21:41 +08:00
这是 andy pavlo 的课吗 我今天也刚看到这里
|
 |
26
snw 2021-07-13 17:37:36 +08:00 via Android 其实吧,SQL 真实的逻辑顺序是:
FROM ... //从某个表中 WHERE ... //筛选出某些行 SELECT ... //返回这些行的某些列的数据 只是为了迎合英文的语法习惯所以规定成了 SELECT ... FROM ... WHERE ... 所以改写一下就比较符合人类阅读了(虽然 SQL 会报错): FROM enrolled as E WHERE cid='15-455' SELECT ( FROM student AS S WHERE S.sid = E.sid SELECT S.name ) AS sname |
 |
27
zxCoder 2021-07-13 18:08:01 +08:00
楼上的解释就比较清楚了
|
 |
28
zhangysh1995 2021-07-13 18:17:55 +08:00
上面都没回答到点上。。
楼主应该问的是为什么我们在一个子语句使用了外层的 E.sid 。 这里需要知道表是否存在 index 。 在有 index 的情况下,第一条语句首先 cid 过滤,然后再比较 S.did = E.sid 的时候,可以直接使用 index,速度比第二条的 IN 要快非常多。因为有 E.sid 的值可以直接 hash index 看 S.sid 的数据置是否存在,只有 E.sid 数量的比较次数 O(E.sid)。 但是对于 IN 来说,它需要比每一条 S.sid 是否在 IN 后面的结果里面,没有 index 情况下 IN 的复杂度是 O(E.sid * S.sid),有 index 情况下 IN 的复杂度是 O(E.sid) 。 这里说的都是理论的复杂度,实际数据库实现中 IN 不一定可以用 index 。 另外一个区别是,因为第一条用了 scalar function, 在进行 cid 过滤的时候,满足的一行会直接送给子查询去判断 S.sid = E.sid 是否存在(这里是因为行变量的值可以传递到子查询),第二条是做完了过滤才去用 IN 查询,所以速度会变慢。 |
|
29
zhangysh1995 2021-07-13 18:21:16 +08:00 楼主如果要知道更多一些关于 SQL 的理论知识,可以考虑看 https://db.inf.uni-tuebingen.de/team/TorstenGrust.html 这位教授的课程,youtube 有视频。CMU 的课程重点是数据库系统本身和现代系统应用,而不是 SQL 。
|
 |
30
Divinook 2021-07-13 18:51:21 +08:00 via Android
@zhangysh1995 exists 也使用外层的字段,楼主应该问的就是 select 为什么也可以用子语句
|

