- 发生了两次不同的 oom
- 第一次:java.lang.OutOfMemoryError:Java heap space
这次有运维的 dump 文件,很容易就分析出来了,改了代码
- 第二次:日志里先出现了 Java heap space ,又出现了 GC overhead limit exceeded
这次据说出问题后很快被别人重启了,运维没来得及 dump 。
关于这两种报错的区别,我在这里找到了答案: https://stackoverflow.com/questions/34329785/java-lang-outofmemoryerror-gc-overhead-limit-exceeded-vs-java-heap-space
我想通过 jvm 的监控指标来验证答案里所说的区别,所以我去看了 grafana 的 jvm 监控页面,但是发现很多指标不懂,可能由于搜索方式不对,也搜不到答案,故来请教一下
-
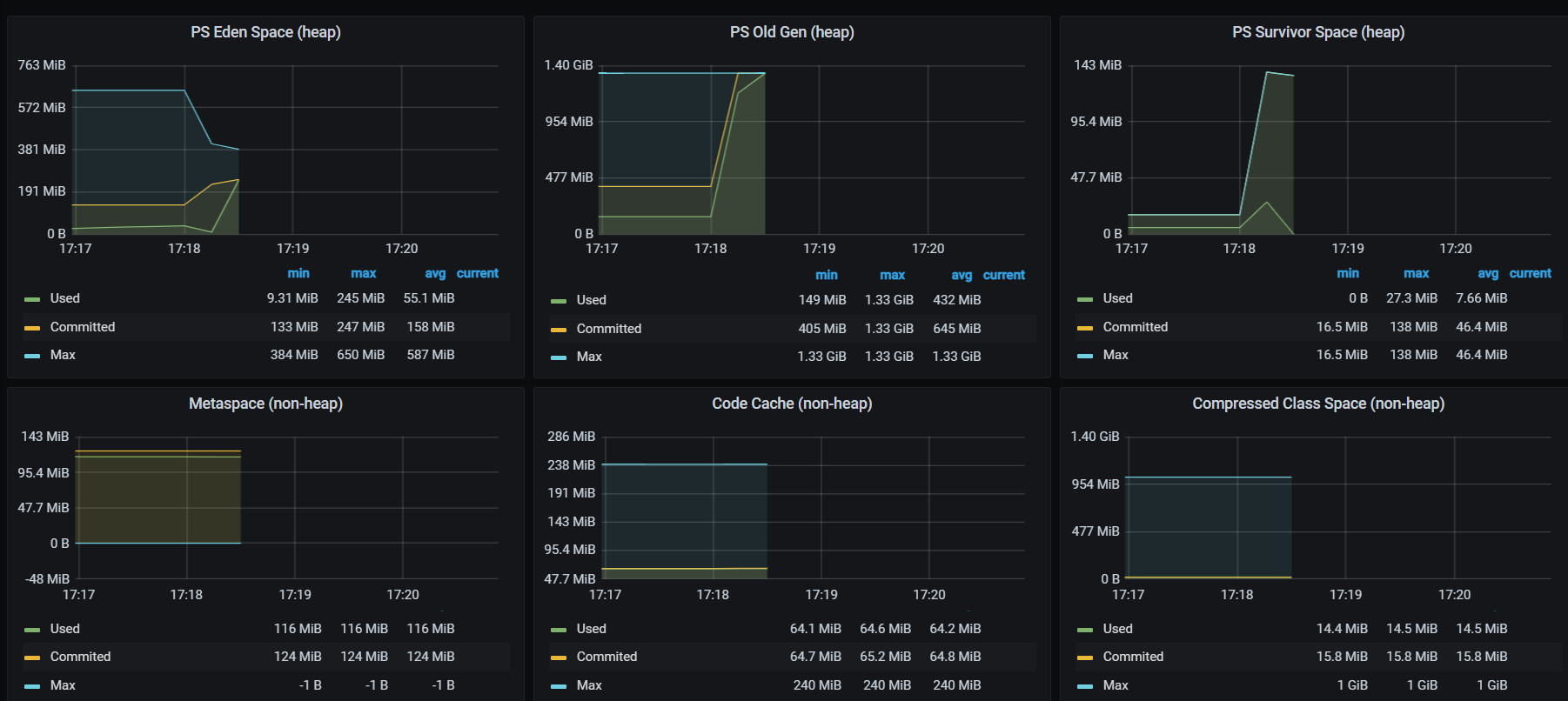
以下是我的疑惑(图片来自于第一次 oom 时的监控页面)
-
问题 1:指标里的 gc count 为什么纵坐标是小数?
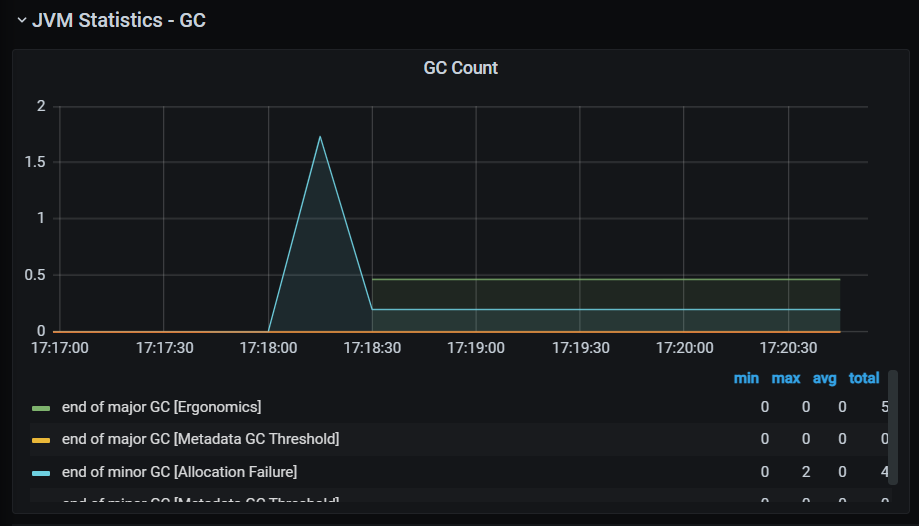
-
问题 2:下图 1 中 promoted 表示老年代增加了 69.9mb 的空间,为什么图 2 的 commit 却增加了快 1g?同理 allocated 又可以在哪里得到体现呢?
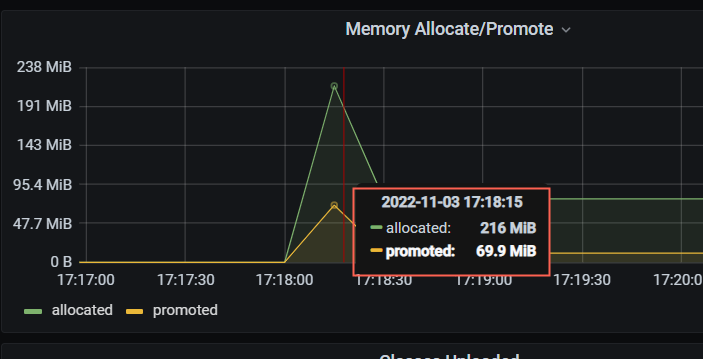
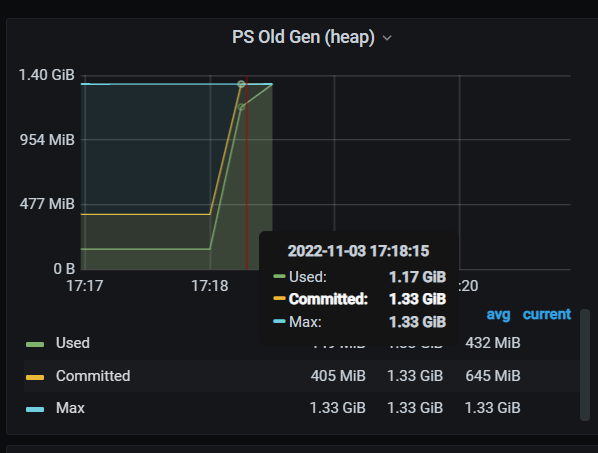
- 更多的图(不确定是否对描述问题有帮助)
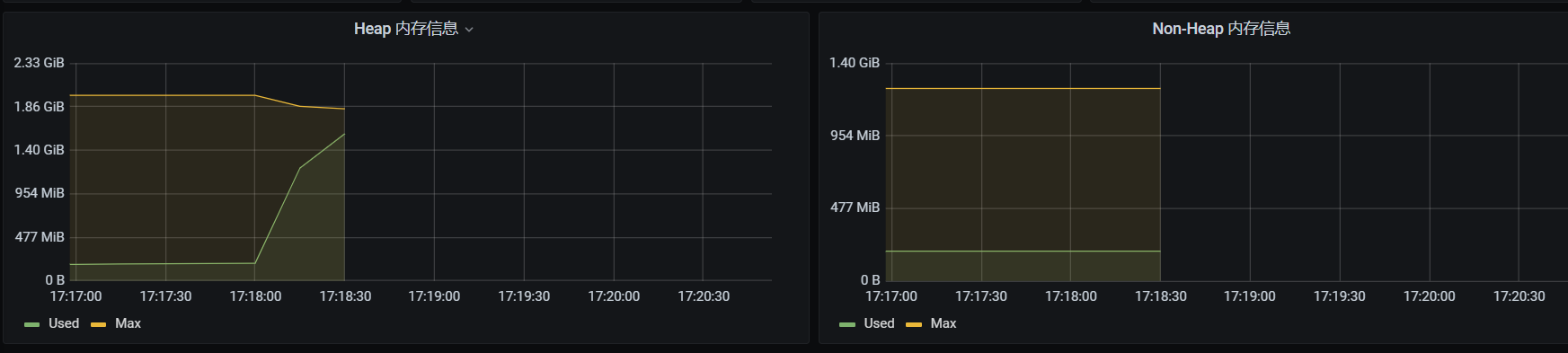
 最后一张图右上角的 commit 和 max 重合了
最后一张图右上角的 commit 和 max 重合了