推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

[干货分享] 用 Python 抓取和分析《安家》评论数据,从观众角度了解这部电视剧
CicadaMan · 2020-03-15 18:51:44 +08:00 · 2859 次点击这是一个创建于 2069 天前的主题,其中的信息可能已经有所发展或是发生改变。
最近最火的电视剧,非《安家》莫属了。这是一部讲述房产中介的故事,有一个中介公司叫做“安家天下”,其中有两个店长,在剧情设定方面,我们就知道,这中间肯定会发生一些有( gou )趣( xue )的故事。因此我用 Python 爬取了豆瓣《安家》下所有的评论,进行了一波分析,从观众的角度来了解这部电视剧。
爬虫部分:
先来讲下技术栈,这个项目我用的是 Scrapy+JSON 的方式实现的。技术难度并不复杂,毕竟豆瓣并不是一个反爬虫很厉害的网站(学爬虫基本上都做过爬取 top250 ),只要设置好 User-Agent 就行。在这里我就大概的描述一下代码过程,想要代码的可以关注众号"pythonjs",然后私信安家,即可获取。
第一步通过 Scrapy 命令创建一个项目和爬虫:
scrapy startproject anjia_scrapy
cd anjia_scrapy
scrapy genspider anjia "douban.com"
然后开始编写爬虫。爬虫部分可以分开来讲一下,首先找到《安家》的评论页面的链接:https://movie.douban.com/subject/30482003/reviews?sort=time&start=0,这个链接是通过 offset 来获取评论的,每一页展示 20 条评论,因此如果要获取下一页的数据,就是设置在当前页面基础上,给 start+20 就行了,这是第一点。然后总共有 38 页(后续页数据没有)因此可以生成一个 range(0,760,20)了。
第二点是评论内容数据,如果超过一定的字数是会隐藏的,看下截图:
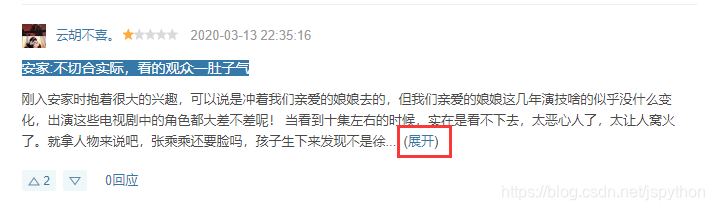
他的这个展开操作,并不是直接在界面上显示一下而已,而是发送了一次网络请求,因此我们还得针对每条评论重新请求一次,链接为:https://movie.douban.com/j/review/12380383/full,其中 review 后面的是这个评论的 id,id 可以在源代码中获取,这里就不再赘述了。
搞清楚了以上两点,我们就可以开始写代码了(数据提取规则这里不展开来讲,有兴趣的可以关注众号"pythonjs",然后私信安家):
class AnjiaSpider(scrapy.Spider):
name = 'anjia'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/subject/30482003/reviews?sort=time&start=0']
def parse(self, response):
# 获取评论标签列表
review_list = response.xpath("//div[contains(@class,'review-list')]/div")
for review_div in review_list:
# 作者
author = review_div.xpath(".//a[@class='name']/text()").get()
# 发布时间
pub_time = review_div.xpath(".//span[@class='main-meta']/text()").get()
# 评分
rating = review_div.xpath(".//span[contains(@class,'main-title-rating')]/@title").get() or ""
# 标题
title = review_div.xpath(".//div[@class='main-bd']/h2/a/text()").get()
# 是否有展开按钮
is_unfold = review_div.xpath(".//a[@class='unfold']")
if is_unfold:
# 获取评论 id
review_id = review_div.xpath(".//div[@class='review-short']/@data-rid").get()
# 获取内容
content = self.get_fold_content(review_id)
else:
content = review_div.xpath(".//div[@class='main-bd']//div[@class='short-content']/text()").get()
if content:
content = re.sub(r"\s",'',content)
# 创建 item 对象
item = AnjiaItem(
author=author,
pub_time=pub_time,
rating=rating,
title=title,
content=content
)
yield item
# 如果有下一页
next_url = response.xpath("//span[@class='next']/a/@href").get()
if next_url:
# 请求下一页的数据
yield scrapy.Request(response.urljoin(next_url),self.parse)
其中发送请求获取完整评论详情用的是 requests 库,代码如下:
def get_fold_content(self,review_id):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
url = "https://movie.douban.com/j/review/{}/full".format(review_id)
resp = requests.get(url,headers=headers)
data = resp.json()
content = data['html']
content = re.sub(r"(<.+?>)","",content)
return content
最后就是编写数据存储的 pipeline 了,这里我是直接存储到 json 文件中,代码如下:
import json
class AnjiaScrapyPipeline(object):
def __init__(self):
self.fp = open("reviews.json", 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(json.dumps(dict(item))+"\n")
return item
def close_spider(self,spider):
self.fp.close()
爬虫比较关键的几个步骤基本上就讲得差不多了,全部代码可以关注众号"pythonjs",然后私信安家获取。
Part.2 数据分析部分
有了数据,我们就可以进行分析了,通过分析我们会发现很多有意思的点。这里我用到的技术栈是 pandas+seaborn 的方式进行分析的,然后代码也是在 jupyter notebook 中写的。以下来进行讲解。(代码获取方式同上)
第一步是读取数据,并将 json 格式的数据转成 DataFrame,毕竟数据分析用 DataFrame 格式会方便很多。代码如下:
items = []
with open("reviews.json","r",encoding='utf-8') as fp:
for line in fp:
review = json.loads(line)
items.append(review)
item_list = [[item['author'],item['pub_time'],item['rating'],item['title'],item['content']] for item in items]
# 构建 DataFrame 对象
review_df = pd.DataFrame(item_list,columns=['author','pub_time','rating','title','content'])
# 删除缺失数值
review_df.dropna(inplace=True)
# 将缺失的评论情况设置为放弃
review_df[review_df['rating']=='']['rating'] = '放弃'
# # 将字符串格式的时间转换为 datatime 类型
review_df['pub_time'] = pd.to_datetime(review_df['pub_time'])
数据已经处理好了,接下来就可以进行分析了。这里我们从几个维度来分析,第一个是评论时间,第二个是评分,第三个是评论内容。
时间我们分成两个点来做,第一个是根据日期来,看下评论随着日期的变化呈现出怎样的趋势。通过 DataFrame 对发布时间的 min 和 max,评论最早是在 2020/02/20,最晚是在 2020/03/14 (也就是我写文章的这一天)。安家的播出时间是在 02/21,如果我们不知道具体的播出时间,实际上通过数据你可以猜个八九不离十。接下来我们就实际动手,来看看随着播放时间的延长,评论数量呈现出怎样的趋势。代码如下,具体细节大家可以看注释:
# 分析评论日期
import re
from matplotlib import dates
plt.figure(figsize=(10,5))
# 2. 添加一个新的 pub_date
review_df['pub_date'] = review_df['pub_time'].dt.date
review_df = review_df[pd.to_datetime(review_df['pub_date']).dt.year>2019]
# # 3. 根据日期分组绘图
review_date_df = review_df.groupby(['pub_date']).count()
ax = sns.lineplot(x=review_date_df.index,y=review_date_df.author,marker='o')
# 设置显示所有时间
ax.set(xticks=review_date_df.index)
# 设置 x 轴旋转
_ = ax.set_xticklabels(review_date_df.index,rotation=45)
# 设置 x 轴格式
ax.xaxis.set_major_formatter(dates.DateFormatter("%m-%d"))
ax.set_xlabel("发布日期")
ax.set_ylabel("评论数量")
最终生成的图如下:
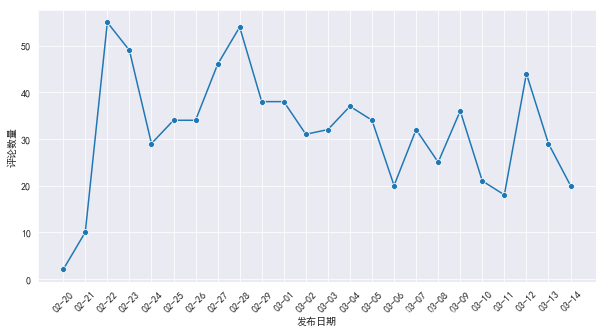
安家从 2 月 21 日开始播放,播放第二天评论数量就一下子冲到 50+,说明这部剧在刚开始播出时还是受到很大的关注。随之评论量降低,但是在 26-29 号之间又来了一拨小高潮,具体电视剧我没咋看,不过从我家人看这电视剧的讨论中来看,那几天应该是发生了什么特别让观众气氛的事情。从这以后,这部电视剧就开始广泛在朋友圈(特别是房产中介)中开始刷屏了。
日期分析完了,我们再来看下时间,看下这些用户一般在哪些时间段评论得比较多。这里我从 0 点到 24 点,2 个小时为一个时间段统计评论数量,代码如下(代码可以关注众号"pythonjs",然后私信安家获取):
# 分析评论时间
import datetime
time_range = [0,2,4,6,8,10,12,14,16,18,20,22,24]
review_time_df = review_df['pub_time'].dt.hour
time_range_counts = pd.cut(review_time_df,bins=time_range,include_lowest=True,right=False).value_counts()
ax = time_range_counts.plot(kind="bar")
_ = ax.set_xticklabels(labels=time_range_counts.index,rotation=45)
最终生成的图如下:
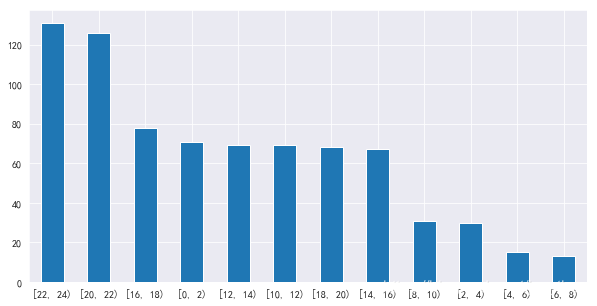
通过分析我们可以看到,排名前 4 的时间段中,在晚上 8 点到凌晨 2 点是评论最多的时候,完全符合当代年轻人的作息时间。估计那些 2 点钟还在评论的,是不是 12 点还在刷剧(说得是不是你☺)。其中有一个比较奇怪的时间,就是下午 4 点到 6 点,评论量是排名第三,这段时间还在评论的小伙伴,“摸鱼”大赛应该都是钻石以上段位了吧。哈哈,剩下的大家可以自行观察,接下来我们进入第二轮分析。
时间方向的分析完了,接下来咱们再来看看评论,这部剧我在网上看到很多批评的评价,那这到底是一部怎么样的剧呢,我们看用户的评分就行。大家都知道,豆瓣的评分是 5 星制,5 星是力荐,4 星是推荐,3 星是还行,2 星是较差,1 星是很差。当然爬取下来的一些数据,由于用户评价的时候没有给分,因此我们给他归类到放弃这部分。代码如下:
# 看下评论好坏的情况
sns.countplot(x='rating',data=review_df,order=review_df['rating'].value_counts().index)
生成的图如下:

排名第一个的是放弃,我们暂且不讨论。不过还行,前两名都是推荐和力荐,占据了评论的绝大部分。当初我在网上看到的评价全是差评,这也提醒了我,我看到的一些信息不能全信,可能只是一叶障目而已。第三名很差,我具体看了下评价 1 星的评论,基本上都是说电视剧和现实中的中介差距很大,剧情太狗血之类的。这也能理解,每个人看剧的角度不同,评价也不一样的。
评价分析完了,我们再来看下观众对角色的情绪。除了剧情狗血,对角色设定的反感也是观众给 1 星的很大一部分原因。这里我的算法是根据评分和内容中出现的角色来进行打分(不是很严谨,但也能说明问题)。举个例子,观众给了 1 星,然后这个评论内容中出现了几次“房似锦”,大概率说明这个观众对“房似锦”这个角色是比较反感的。其次,1 星给 1 分,2 星给 2 分,依次类推,谁的分高,说明谁更受观众喜爱。对内容的分词,用的是 jieba。实现的代码如下:
# 电视剧人物的评分
# 力荐:+5,推荐:+4,还行:3,较差:2,很差:1
roles = {'房似锦':0,'徐文昌':0,'张乘乘':0,'王子健':0,'楼山关':0,'朱闪闪':0,'谢亭丰':0,'鱼化龙':0,'宫蓓蓓':0,'阚文涛':0}
role_names = list(roles.keys())
for name in role_names:
jieba.add_word(name)
for row in review_df.index:
rating = review_df.loc[row,'rating']
if rating:
content = review_df.loc[row,"content"]
words = list(jieba.cut(content, cut_all=False))
names = set(role_names).intersection(set(words))
for name in names:
if rating == '力荐':
roles[name] += 5
elif rating == '推荐':
roles[name] += 4
elif rating == '还行':
roles[name] =3
elif rating == '较差':
roles[name] += 2
elif rating == '很差':
roles[name] += 1
role_df = pd.DataFrame(list(roles.values()),index=list(roles.keys()),columns=['得分'])
role_df.sort_values('得分',inplace=True,ascending=False)
role_df.plot(kind='bar')
绘制出来的图如下:
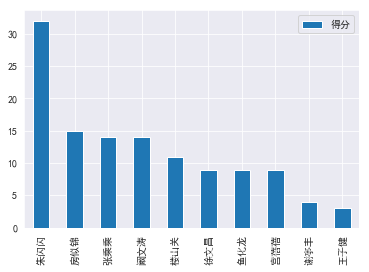
朱闪闪得分居然最高?王子健得分最低?完全出乎我的意料,所以观众到底喜欢什么角色,有些时候不通过数据来看,你是真的想象不到...
最后一步,我们来把评论的文字进行分词,然后制作成一个词云,从词云中可以明显的看出文字出现的概率和次数。制作词云的代码如下:
def generate_wc(string_data):
# 文本预处理
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"') # 定义正则表达式匹配模式
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除
# 文本分词
seg_list_exact = jieba.cut(string_data, cut_all = False) # 精确模式分词
object_list = []
remove_words = []
with open("停用词库.txt",'r',encoding='utf-8') as fp:
for word in fp:
remove_words.append(word.replace("\n",""))
for word in seg_list_exact: # 循环读出每个分词
if word not in remove_words: # 如果不在去除词库中
object_list.append(word) # 分词追加到列表
# 词频统计
word_counts = collections.Counter(object_list) # 对分词做词频统计
# 词频展示
wc = wordcloud.WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体格式
background_color="#000000", # 设置背景图
max_words=150, # 最多显示词数
max_font_size=60, # 字体最大值
width=707,
height=490
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
content_str = ""
for row in review_df.index:
content = review_df.loc[row,'content']
content_str += content
generate_wc(content_str)
生成的词云效果如下(颜色搭配有些鸡肋):

房似锦和孙俪是出现的频率都很高,说明这个演员还是很受关注呀。另外房子,店长,客户,专业,行业,安家等都是高频词汇。不看电视从这个图中八九不离十就能猜到这是一部讲房产中介的电视剧啦。
因为篇幅原因,没有继续分析下去了,大家如果感兴趣,可以关注关注众号"pythonjs",然后私信安家即可获得本文所有代码。让我们一起进步吧,加油! 奥里给!!
 |
1
lenkaren 2020-03-16 09:15:11 +08:00
刚好最近在学 Python 搞数据分析,支持一下
|
