
这是一个创建于 2115 天前的主题,其中的信息可能已经有所发展或是发生改变。
Go 数据类型有如下类型。
- 基础类型
- 复合类型
- 引用类型
- 接口类型 类型内容很多只能慢慢学习,今天学习复合类型。
复合类型
符合类型分类
- 固定长度
- 数组
- 结构体
- 动态长度
- slice
- map
类型详解
- 数组:数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成
- 我们将会发现,数组、slice、map 和结构体字面值的写法都很相似。是直接提供顺序初始化值序列,但是也可以指定一个索引和对应值列表的方式初始化,就像下面这样:
type Currency int const ( USD Currency = iota // 美元 EUR // 欧元 GBP // 英镑 RMB // 人民币 ) symbol := [...]string{USD: "$", EUR: "€", GBP: "£", RMB: "¥"} fmt.Println(RMB, symbol[RMB]) // "3 ¥"- 数组是可以直接比较的
import "crypto/sha256" func main() { c1 := sha256.Sum256([]byte("x")) c2 := sha256.Sum256([]byte("X")) fmt.Printf("%x\n%x\n%t\n%T\n", c1, c2, c1 == c2, c1) // Output: //2d711642b726b04401627ca9fbac32f5c8530fb1903cc4db02258717921a4881 // 4b68ab3847feda7d6c62c1fbcbeebfa35eab7351ed5e78f4ddadea5df64b8015 // false // [32]uint8 }- Go 语言对待数组的方式和其它很多编程语言不同,其它编程语言可能会隐式地将数组作为引用或指针对象传入被调用的函数。
因为函数对待参数是值传递,需要复制参数变量,有些变成语言回见数据组隐式的转换为引用,以减少复制大型参数造成的额外开销。
- 虽然通过指针来传递数组参数是高效的,而且也允许在函数内部修改数组的值,但是数组依然是僵化的类型,因为数组的类型包含了僵化的长度信息。由于这些原因,除了像 SHA256 这类需要处理特定大小数组的特例外,数组依然很少用作函数参数;相反,我们一般使用 slice 来替代数组。
- slice:底层是用数组实现的,支持动态的扩容
- 组成
- 指针:指针指向第一个 slice 元素对应的底层数组元素的地址,要注意的是 slice 的第一个元素并不一定就是数组的第一个元素
- 长度:长度对应 slice 中元素的数目,长度不能超过容量
- 容量:容量一般是从 slice 的开始位置到底层数据的结尾位置。内置的 len 和 cap 函数分别返回 slice 的长度和容量。
- 多个 slice 之间可以共享底层的数据,并且引用的数组部分区间可能重叠。图 4.1 显示了表示一年中每个月份名字的字符串数组,还有重叠引用了该数组的两个 slice。
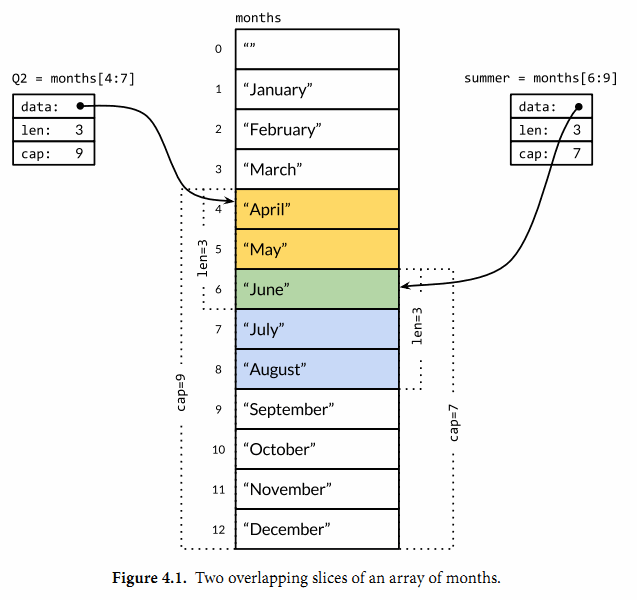
- 因为 slice 值包含指向第一个 slice 元素的指针,因此向函数传递 slice 将允许在函数内部修改底层数组的元素。换句话说,复制一个 slice 只是对底层的数组创建了一个新的 slice 别名。下面的 reverse 函数在原内存空间将[]int 类型的 slice 反转,而且它可以用于任意长度的 slice。
func reverse(s []int) { for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 { s[i], s[j] = s[j], s[i] } } a := [...]int{0, 1, 2, 3, 4, 5} reverse(a[:]) fmt.Println(a) // "[5 4 3 2 1 0]"- slice 底层是数组但并不能像数组一样比较。
- 一个原因 slice 的元素是间接引用的,一个 slice 甚至可以包含自身
- 第二个原因,因为 slice 的元素是间接引用的,一个固定的 slice 值(译注:指 slice 本身的值,不是元素的值)在不同的时刻可能包含不同的元素,因为底层数组的元素可能会被修改。slice 扩容是地址也会发生改变。鉴于安全考虑直接禁止 slice 之间的比较操作,简化复杂度。
- 判断空 slice
- 如果你需要测试一个 slice 是否是空的,使用 len(s) == 0 来判断,而不应该用 s == nil 来判断。
- 组成
- 结构体:相当于类
- 一个命名为 S 的结构体类型将不能再包含 S 类型的成员:因为一个聚合的值不能包含它自身。(该限制同样适应于数组。)但是 S 类型的结构体可以包含*S 指针类型的成员,这可以让我们创建递归的数据结构,比如链表和树结构等。
- Go 语言有一个特性让我们只声明一个成员对应的数据类型而不指名成员的名字;这类成员就叫匿名成员。匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针。下面的代码中,Circle 和 Wheel 各自都有一个匿名成员。我们可以说 Point 类型被嵌入到了 Circle 结构体,同时 Circle 类型被嵌入到了 Wheel 结构体。
type Point struct { X, Y int } type Circle struct { Center Point Radius int } type Wheel struct { Circle Circle Spokes int } var w Wheel w.X = 8 // equivalent to w.Circle.Point.X = 8 w.Y = 8 // equivalent to w.Circle.Point.Y = 8 w.Radius = 5 // equivalent to w.Circle.Radius = 5 w.Spokes = 20- 在右边的注释中给出的显式形式访问这些叶子成员的语法依然有效,因此匿名成员并不是真的无法访问了。其中匿名成员 Circle 和 Point 都有自己的名字——就是命名的类型名字——但是这些名字在点操作符中是可选的。我们在访问子成员的时候可以忽略任何匿名成员部分。
- map
- map 底层也是固定数组,通过哈希表映射
- map 中的元素并不是一个变量,因此我们不能对 map 的元素进行取址操作,禁止对 map 元素取址的原因是 map 可能随着元素数量的增长而重新分配更大的内存空间,从而可能导致之前的地址无效。
- Map 的迭代顺序是不确定的,并且不同的哈希函数实现可能导致不同的遍历顺序。在实践中,遍历的顺序是随机的,每一次遍历的顺序都不相同。这是故意的,每次都使用随机的遍历顺序可以强制要求程序不会依赖具体的哈希函数实现。
总结
类型就是数据结构,写代码先定义数据结构,数据结构决定了代码的走向决定了用什么算法。学海无涯苦作舟,千帆过尽还复来。继续努力吧。
目前尚无回复