
关于 Tensorflow 使用 Dataset API 占用内存高的问题
tomleung1996 · 2019-02-24 21:18:58 +08:00 · 2401 次点击这是一个创建于 2126 天前的主题,其中的信息可能已经有所发展或是发生改变。
初学深度学习,看的是《 Hands on Machine Learning with Scikit-Learn and Tensorflow 》这本书,书中用自己定义的shuffle_batch函数实现将数据分批输入神经网络的功能,数据集用的是 MNIST。
书上的函数定义如下:
def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
楼主上网搜索一下发现用 Dataset API 和它的shuffle、batch和repeat函数可能可以更加优雅地实现分批输入的功能,于是就写了下面的代码:
train_data = tf.data.Dataset.from_tensor_slices((X_train, y_train))
train_data = train_data.shuffle(m)
train_data = train_data.batch(batch_size)
train_data = train_data.repeat()
td_iter = train_data.make_one_shot_iterator()
features, labels = td_iter.get_next()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for iteration in range(n_batchs):
X_batch, y_batch = sess.run([features, labels])
sess.run(training_op, feed_dict={X:X_batch, y:y_batch})
acc_train = accuracy.eval(feed_dict={X:X_batch, y:y_batch})
acc_test = accuracy.eval(feed_dict={X:X_test, y:y_test})
print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
save_path = saver.save(sess, './my_model')
但是我发现这段代码虽然也能训练出类似精度的模型,但是在打印出第一个 epoch 的输出前,内存占用极高,而且要等好久才会有第一个输出(后面的输出就花费正常时间)。
如果是按照书上的代码来训练(不使用 Dataset API ),内存几乎没有任何波动。但是我觉得就算是用了 Dataset API,MNIST 这个数据集也不大吧?要占用这么多内存么?
同样的内存占用情况也发生在下面的代码:
with tf.Session() as sess:
sess.run(init)
sess.run([features, labels])
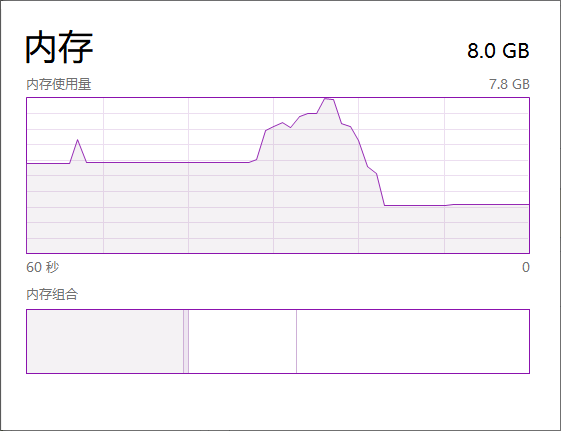
我觉得是不是我代码哪里写错了?因为刚接触这个 API,是模仿人家的写法写的,希望大家解答下疑惑哈
目前尚无回复