V2EX = way to explore
V2EX 是一个关于分享和探索的地方
Sign Up Now
For Existing Member Sign In
推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

This topic created in 2650 days ago, the information mentioned may be changed or developed.
用的 python
这张图片识别成了 BS...
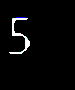
识别信息:
Tesseract Open Source OCR Engine v4.0.0.20181030 with Leptonica Warning: Invalid resolution 0 dpi. Using 70 instead. BS
版本:
$ D:\Tesseract-OCR\tesseract.exe -v tesseract v4.0.0.20181030 leptonica-1.76.0 libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.2.0
我已经尝试了, 把转换为 tiff 格式, 用 OpenCV 的 threshold 和 erosion 处理都不行, 我想 tesseract 的识别能力不至于这么差吧。。。 这个图片我觉得已经很简单了。
有那个老哥有相关的经验, 或者有什么其他的方法, 在线的 ocr 速度不行我这个最好还是本地的 OCR 比较好。 主要识别数字, 今天刚下载的 tesseract...
 |
1
diggerdu Feb 2, 2019 via iPhone
不用 lstm 呢
|
 |
2
realpg PRO 这个图片你觉得很简单了
你到现在还没理解最基本的计算机和人的区别…… |
 |
3
alvin666 Feb 2, 2019 via Android
炼丹吧少年
|
 |
4
cjq8z Feb 3, 2019 via Android
用下面语句,tesseract myimage.png stdout -c tessedit_char_whitelist=0123456789
|
 |
5
whstarlit Feb 3, 2019
tesseract 配置里改成只识别 0-9 数字,然后识别用 -psm 10
|
 |
6
laqow Feb 3, 2019 via Android
没下载好一点的训练文件,没指定 psm
|
 |
7
nicevar Feb 3, 2019
很明显你没配置好
pytesseract.image_to_string(image, config='./tessdata') 指定好 testdata 目录就行了 |