
这是一个创建于 2662 天前的主题,其中的信息可能已经有所发展或是发生改变。
1. CRI 简介
在每个 Kubernetes 节点的最底层都有一个程序负责具体的容器创建删除工作,Kubernetes 会对其接口进行调用,从而完成容器的编排调度。我们将这一层软件称之为容器运行时( Container Runtime ),大名鼎鼎的 Docker 就是其中的代表。
当然,容器运行时并非只有 Docker 一种,包括 CoreOS 的 rkt,hyper.sh 的 runV,Google 的 gvisor,以及本文的主角 PouchContainer,都包含了完整的容器操作,能够用来创建特性各异的容器。不同的容器运行时有着各自独特的优点,能够满足不同用户的需求,因此 Kubernetes 支持多种容器运行时势在必行。
最初,Kubernetes 原生内置了对 Docker 的调用接口,之后社区又在 Kubernetes 1.3 中集成了 rkt 的接口,使其成为了 Docker 以外,另一个可选的容器运行时。不过,此时不论是对于 Docker 还是对于 rkt 的调用都是和 Kubernetes 的核心代码强耦合的,这无疑会带来如下两方面的问题:
- 新兴的容器运行时,例如 PouchContainer 这样的后起之秀,加入 Kubernetes 生态难度颇大。容器运行时的开发者必须对于 Kubernetes 的代码(至少是 Kubelet )有着非常深入的理解,才能顺利完成两者之间的对接。
- Kubernetes 的代码将更加难以维护,这也体现在两方面:( 1 )将各种容器运行时的调用接口全部硬编码进 Kubernetes,会让 Kubernetes 的核心代码变得臃肿不堪,( 2 )容器运行时接口细微的改动都会引发 Kubernetes 核心代码的修改,增加 Kubernetes 的不稳定性
为了解决这些问题,社区在 Kubernetes 1.5 引入了 CRI ( Container Runtime Interface ),通过定义一组容器运行时的公共接口将 Kubernetes 对于各种容器运行时的调用接口屏蔽至核心代码以外,Kubernetes 核心代码只对该抽象接口层进行调用。而对于各种容器运行时,只要满足了 CRI 中定义的各个接口就能顺利接入 Kubernetes,成为其中的一个容器运行时选项。方案虽然简单,但是对于 Kubernetes 社区维护者和容器运行时开发者来说,都是一种解放。
2. CRI 设计概述
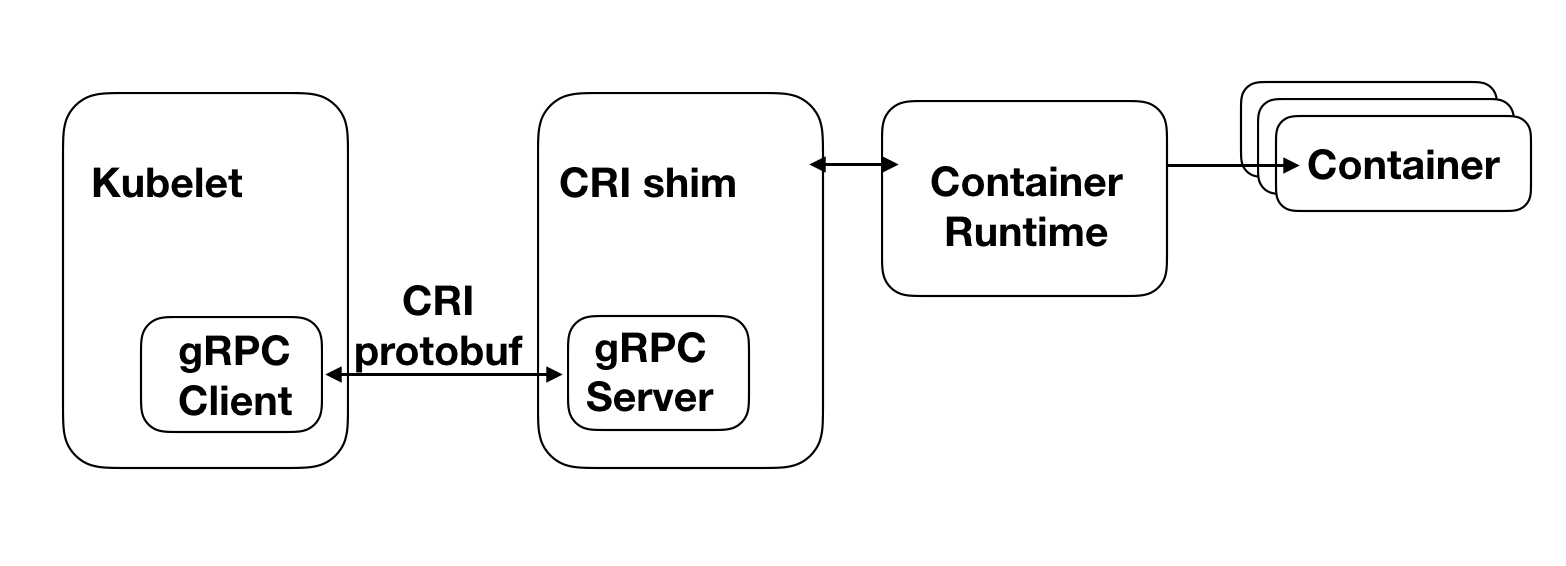
如上图所示,左边的 Kubelet 是 Kubernetes 集群的 Node Agent,它会对本节点上容器的状态进行监控,保证它们都按照预期状态运行。为了实现这一目标,Kubelet 会不断调用相关的 CRI 接口来对容器进行同步。
CRI shim 则可以认为是一个接口转换层,它会将 CRI 接口,转换成对应底层容器运行时的接口,并调用执行,返回结果。对于有的容器运行时,CRI shim 是作为一个独立的进程存在的,例如当选用 Docker 为 Kubernetes 的容器运行时,Kubelet 初始化时,会附带启动一个 Docker shim 进程,它就是 Docker 的 CRI shime。而对于 PouchContainer,它的 CRI shim 则是内嵌在 Pouchd 中的,我们将其称之为 CRI manager。关于这一点,我们会在下一节讨论 PouchContainer 相关架构时再详细叙述。
CRI 本质上是一套 gRPC 接口,Kubelet 内置了一个 gRPC Client,CRI shim 中则内置了一个 gRPC Server。Kubelet 每一次对 CRI 接口的调用,都将转换为 gRPC 请求由 gRPC Client 发送给 CRI shim 中的 gRPC Server。Server 调用底层的容器运行时对请求进行处理并返回结果,由此完成一次 CRI 接口调用。
CRI 定义的 gRPC 接口可划分两类,ImageService 和 RuntimeService:其中 ImageService 负责管理容器的镜像,而 RuntimeService 则负责对容器生命周期进行管理以及与容器进行交互( exec/attach/port-forward )。
3. CRI Manager 架构设计
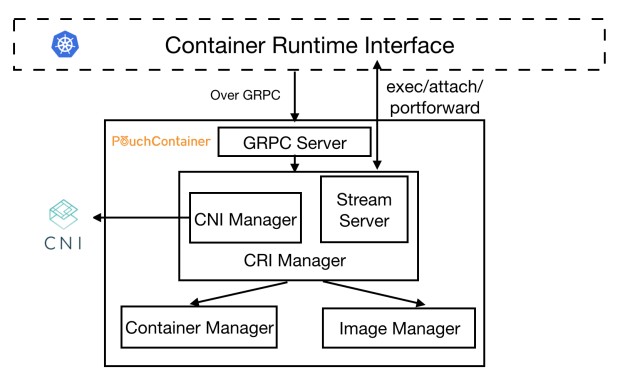
在 PouchContainer 的整个架构体系中,CRI Manager 实现了 CRI 定义的全部接口,担任了 PouchContainer 中 CRI shim 的角色。当 Kubelet 调用一个 CRI 接口时,请求就会通过 Kubelet 的 gRPC Client 发送到上图的 gRPC Server 中。Server 会对请求进行解析,并调用 CRI Manager 相应的方法进行处理。
我们先通过一个例子来简单了解一下各个模块的功能。例如,当到达的请求为创建一个 Pod,那么 CRI Manager 会先将获取到的 CRI 格式的配置转换成符合 PouchContainer 接口要求的格式,调用 Image Manager 拉取所需的镜像,再调用 Container Manager 创建所需的容器,并调用 CNI Manager,利用 CNI 插件对 Pod 的网络进行配置。最后,Stream Server 会对交互类型的 CRI 请求,例如 exec/attach/portforward 进行处理。
值得注意的是,CNI Manager 和 Stream Server 是 CRI Manager 的子模块,而 CRI Manager,Container Manager 以及 Image Manager 是三个平等的模块,它们都位于同一个二进制文件 Pouchd 中,因此它们之间的调用都是最为直接的函数调用,并不存在例如 Docker shim 与 Docker 交互时,所需要的远程调用开销。下面,我们将进入 CRI Manager 内部,对其中重要功能的实现做更为深入的理解。
4. Pod 模型的实现
在 Kubernetes 的世界里,Pod 是最小的调度部署单元。简单地说,一个 Pod 就是由一些关联较为紧密的容器构成的容器组。作为一个整体,这些“亲密”的容器之间会共享一些东西,从而让它们之间的交互更为高效。例如,对于网络,同一个 Pod 中的容器会共享同一个 IP 地址和端口空间,从而使它们能直接通过 localhost 互相访问。对于存储,Pod 中定义的 volume 会挂载到其中的每个容器中,从而让每个容器都能对其进行访问。
事实上,只要一组容器之间共享某些 Linux Namespace 以及挂载相同的 volume 就能实现上述的所有特性。下面,我们就通过创建一个具体的 Pod 来分析 PouchContainer 中的 CRI Manager 是如何实现 Pod 模型的:
- 当 Kubelet 需要新建一个 Pod 时,首先会对
RunPodSandbox这一 CRI 接口进行调用,而 CRI Manager 对该接口的实现是创建一个我们称之为"infra container"的特殊容器。从容器实现的角度来看,它并不特殊,无非是调用 Container Manager,创建一个镜像为pause-amd64:3.0的普通容器。但是从整个 Pod 容器组的角度来看,它是有着特殊作用的,正是它将自己的 Linux Namespace 贡献出来,作为上文所说的各容器共享的 Linux Namespace,将容器组中的所有容器联结到一起。它更像是一个载体,承载了 Pod 中所有其他的容器,为它们的运行提供基础设施。而一般我们也用 infra container 代表一个 Pod。 - 在 infra container 创建完成之后,Kubelet 会对 Pod 容器组中的其他容器进行创建。每创建一个容器就是连续调用
CreateContainer和StartContainer这两个 CRI 接口。对于CreateContainer,CRI Manager 仅仅只是将 CRI 格式的容器配置转换为 PouchContainer 格式的容器配置,再将其传递给 Container Manager,由其完成具体的容器创建工作。这里我们唯一需要关心的问题是,该容器如何加入上文中提到的 infra container 的 Linux Namespace。其实真正的实现非常简单,在 Container Manager 的容器配置参数中有PidMode,IpcMode以及NetworkMode三个参数,分别用于配置容器的 Pid Namespace,Ipc Namespace 和 Network Namespace。笼统地说,对于容器的 Namespace 的配置一般都有两种模式:"None"模式,即创建该容器自己独有的 Namespace,另一种即为"Container"模式,即加入另一个容器的 Namespace。显然,我们只需要将上述三个参数配置为"Container"模式,加入 infra container 的 Namespace 即可。具体是如何加入的,CRI Manager 并不需要关心。对于StartContainer,CRI Manager 仅仅只是做了一层转发,从请求中获取容器 ID 并调用 Container Manager 的Start接口启动容器。 - 最后,Kubelet 会不断调用
ListPodSandbox和ListContainers这两个 CRI 接口来获取本节点上容器的运行状态。其中ListPodSandbox罗列的其实就是各个 infra container 的状态,而ListContainer罗列的是除了 infra container 以外其他容器的状态。现在问题是,对于 Container Manager 来说,infra container 和其他 container 并不存在任何区别。那么 CRI Manager 是如何对这些容器进行区分的呢?事实上,CRI Manager 在创建容器时,会在已有容器配置的基础之上,额外增加一个 label,标志该容器的类型。从而在实现ListPodSandbox和ListContainers接口的时候,以该 label 的值作为条件,就能对不同类型的容器进行过滤。
综上,对于 Pod 的创建,我们可以概述为先创建 infra container,再创建 pod 中的其他容器,并让它们加入 infra container 的 Linux Namespace。
5. Pod 网络配置
因为 Pod 中所有的容器都是共享 Network Namespace 的,因此我们只需要在创建 infra container 的时候,对它的 Network Namespace 进行配置即可。
在 Kubernetes 生态体系中容器的网络功能都是由 CNI 实现的。和 CRI 类似,CNI 也是一套标准接口,各种网络方案只要实现了该接口就能无缝接入 Kubernetes。CRI Manager 中的 CNI Manager 就是对 CNI 的简单封装。它在初始化的过程中会加载目录/etc/cni/net.d下的配置文件,如下所示:
$ cat >/etc/cni/net.d/10-mynet.conflist <<EOF
{
"cniVersion": "0.3.0",
"name": "mynet",
"plugins": [
{
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.22.0.0/16",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
]
}
EOF
其中指定了配置 Pod 网络会使用到的 CNI 插件,例如上文中的bridge,以及一些网络配置信息,例如本节点 Pod 所属的子网范围和路由配置。
下面我们就通过具体的步骤来展示如何将一个 Pod 加入 CNI 网络:
- 当调用 container manager 创建 infra container 时,将
NetworkMode设置为"None"模式,表示创建一个该 infra container 独有的 Network Namespace 且不做任何配置。 - 根据 infra container 对应的 PID,获取其对应的 Network Namespace 路径
/proc/{pid}/ns/net。 - 调用 CNI Manager 的
SetUpPodNetwork方法,核心参数为步骤二中获取的 Network Namespace 路径。该方法做的工作就是调用 CNI Manager 初始化时指定的 CNI 插件,例如上文中的 bridge,对参数中指定的 Network Namespace 进行配置,包括创建各种网络设备,进行各种网络配置,将该 Network Namespace 加入插件对应的 CNI 网络中。
对于大多数 Pod,网络配置都是按照上述步骤操作的,大部分的工作将由 CNI 以及对应的 CNI 插件替我们完成。但是对于一些特殊的 Pod,它们会将自己的网络模式设置为"Host",即和宿主机共享 Network Namespace。这时,我们只需要在调用 Container Manager 创建 infra container 时,将NetworkMode设置为"Host",并且跳过 CNI Manager 的配置即可。
对于 Pod 中其他的容器,不论 Pod 是处于"Host"网络模式,还是拥有独立的 Network Namespace,都只需要在调用 Container Manager 创建容器时,将NetworkMode配置为"Container"模式,加入 infra container 所在的 Network Namespace 即可。
6. IO 流处理
Kubernetes 提供了例如kubectl exec/attach/port-forward这样的功能来实现用户和某个具体的 Pod 或者容器的直接交互。如下所示:
aster $ kubectl exec -it shell-demo -- /bin/bash
root@shell-demo:/# ls
bin dev home lib64 mnt proc run srv tmp var
boot etc lib media opt root sbin sys usr
root@shell-demo:/#
可以看到,exec一个 Pod 等效于ssh登录到该容器中。下面,我们根据kubectl exec的执行流来分析 Kubernetes 中对于 IO 请求的处理,以及 CRI Manager 在其中扮演的角色。
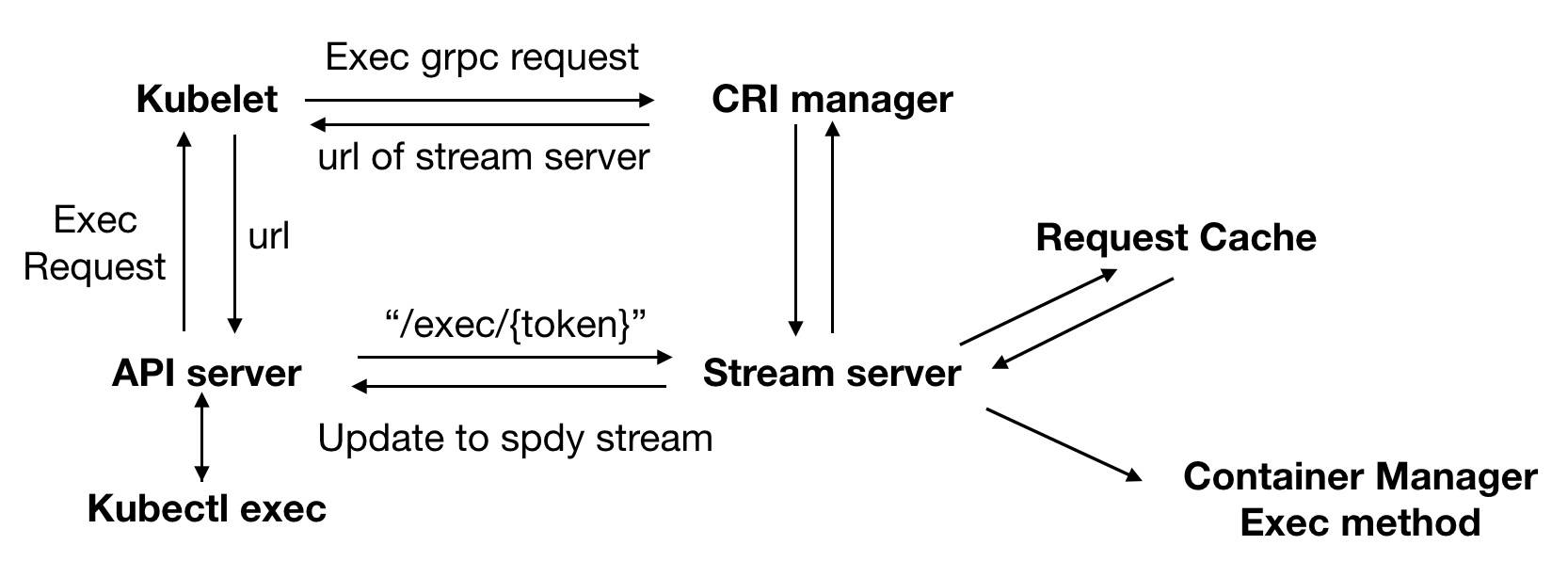
如上图所示,执行一条kubectl exec命令的步骤如下:
-
kubectl exec命令的本质其实是对 Kubernetes 集群中某个容器执行 exec 命令,并将由此产生的 IO 流转发到用户的手中。所以请求将首先层层转发到达该容器所在节点的 Kubelet,Kubelet 再根据配置调用 CRI 中的Exec接口。请求的配置参数如下:type ExecRequest struct { ContainerId string // 执行 exec 的目标容器 Cmd []string // 具体执行的 exec 命令 Tty bool // 是否在一个 TTY 中执行 exec 命令 Stdin bool // 是否包含 Stdin 流 Stdout bool // 是否包含 Stdout 流 Stderr bool // 是否包含 Stderr 流 } -
令人感到意外的是,CRI Manager 的
Exec方法并没有直接调用 Container Manager,对目标容器执行 exec 命令,而是转而调用了其内置的 Stream Server 的GetExec方法。 -
Stream Server 的
GetExec方法所做的工作是将该 exec 请求的内容保存到了上图所示的 Request Cache 中,并返回一个 token,利用该 token,我们可以重新从 Request Cache 中找回对应的 exec 请求。最后,将这个 token 写入一个 URL 中,并作为执行结果层层返回到 ApiServer。 -
ApiServer 利用返回的 URL 直接对目标容器所在节点的 Stream Server 发起一个 http 请求,请求的头部包含了"Upgrade"字段,要求将 http 协议升级为 websocket 或者 SPDY 这样的 streaming protocol,用于支持多条 IO 流的处理,本文我们以 SPDY 为例。
-
Stream Server 对 ApiServer 发送的请求进行处理,首先根据 URL 中的 token,从 Request Cache 中获取之前保存的 exec 请求配置。之后,回复该 http 请求,同意将协议升级为 SPDY,并根据 exec 请求的配置等待 ApiServer 创建指定数量的 stream,分别对应标准输入 Stdin,标准输出 Stdout,标准错误输出 Stderr。
-
待 Stream Server 获取指定数量的 Stream 之后,依次调用 Container Manager 的
CreateExec和startExec方法,对目标容器执行 exec 操作并将 IO 流转发至对应的各个 stream 中。 -
最后,ApiServer 将各个 stream 的数据转发至用户,开启用户与目标容器的 IO 交互。
事实上,在引入 CRI 之前,Kubernetes 对于 IO 的处理方式和我们的预期是一致的,Kubelet 会直接对目标容器执行 exec 命令,并将 IO 流转发回 ApiServer。但是这样会让 Kubelet 承载过大的压力,所有的 IO 流都需要经过它的转发,这显然是不必要的。因此上述的处理虽然初看较为复杂,但是有效地缓解了 Kubelet 的压力,并且也让 IO 的处理更为高效。
7. 总结
本文从引入 CRI 的缘由而起,简要描述了 CRI 的架构,重点叙述了 PouchContainer 对 CRI 各个核心功能模块的实现。CRI 的存在让 PouchContainer 容器加入 Kubernetes 生态变得更为简单快捷。而我们也相信,PouchContainer 独有的特性必定会让 Kubernetes 生态变得更加丰富多彩。
参考文献
目前尚无回复