
这是一个创建于 2804 天前的主题,其中的信息可能已经有所发展或是发生改变。
hadoop 用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。云计算大数据到现在是越来越火,而 hadoop 成为大数据不可或缺的分布式大数据计算平台。
Hadoop实现了一个分布式文件系统( Hadoop Distributed File System ),简称 HDFS 。 HDFS 有高容错性的特点,并且设计用来部署在低廉的( low-cost )硬件上;而且它提供高吞吐量( high throughput )来访问应用程序的数据,适合那些有着超大数据集( large data set )的应用程序。 HDFS 放宽了( relax ) POSIX 的要求,可以以流的形式访问( streaming access )文件系统中的数据。
今天就先教大家如何搭建伪分布式系统。
首先我们准备一台云服务器 内存 1G 操作系统 centos 7 IP 地址是 211.159.153.214:22
下载地址
https://share.weiyun.com/51a2b349ba1587d69664ad50b7cded3c
首先我们用 XSell 链接(当然大家也可以用别的软件来连接)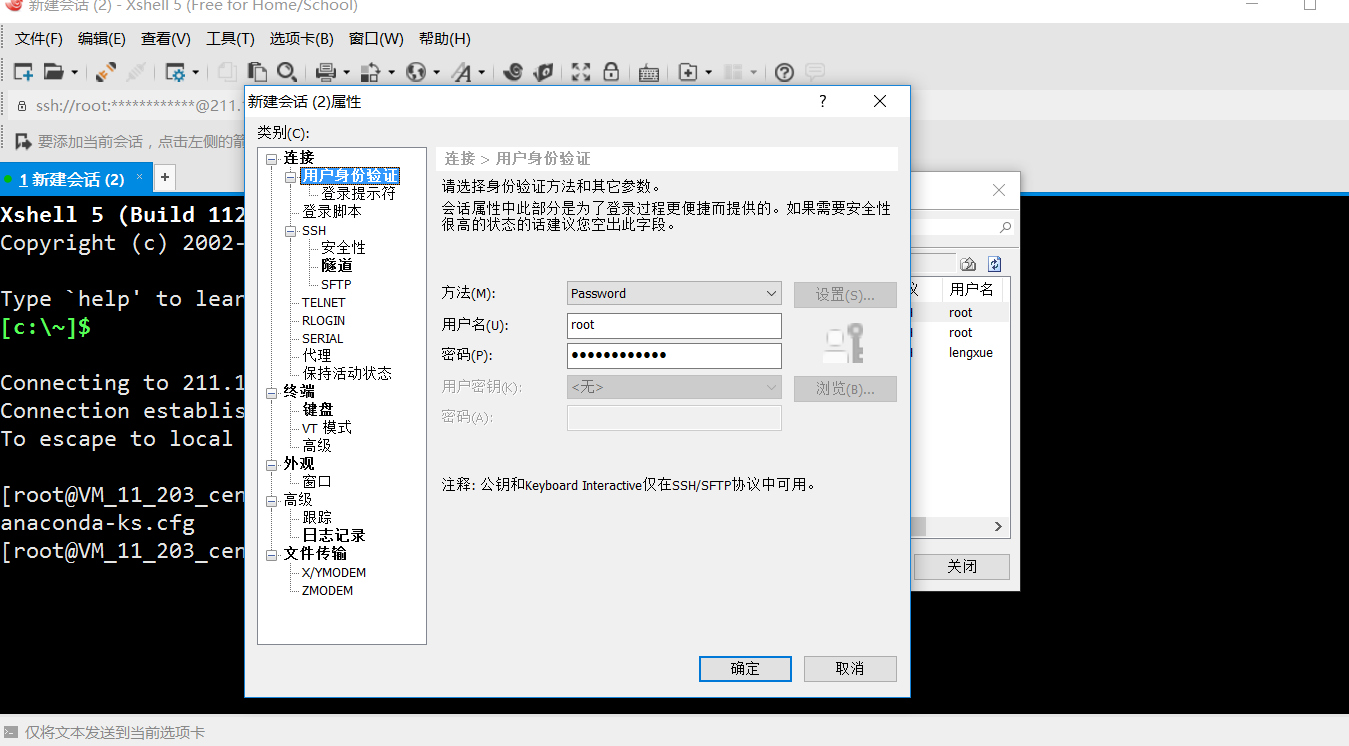
登录后我们就开始搭建我们的 hadoop 伪分布式系统
修改主机名与 IP 地址的对应关系
[root@VM_11_203_centos ~]# hostname
查看主机名[root@VM_11_203_centos ~]# vim /etc/hosts
修改文件为一下内容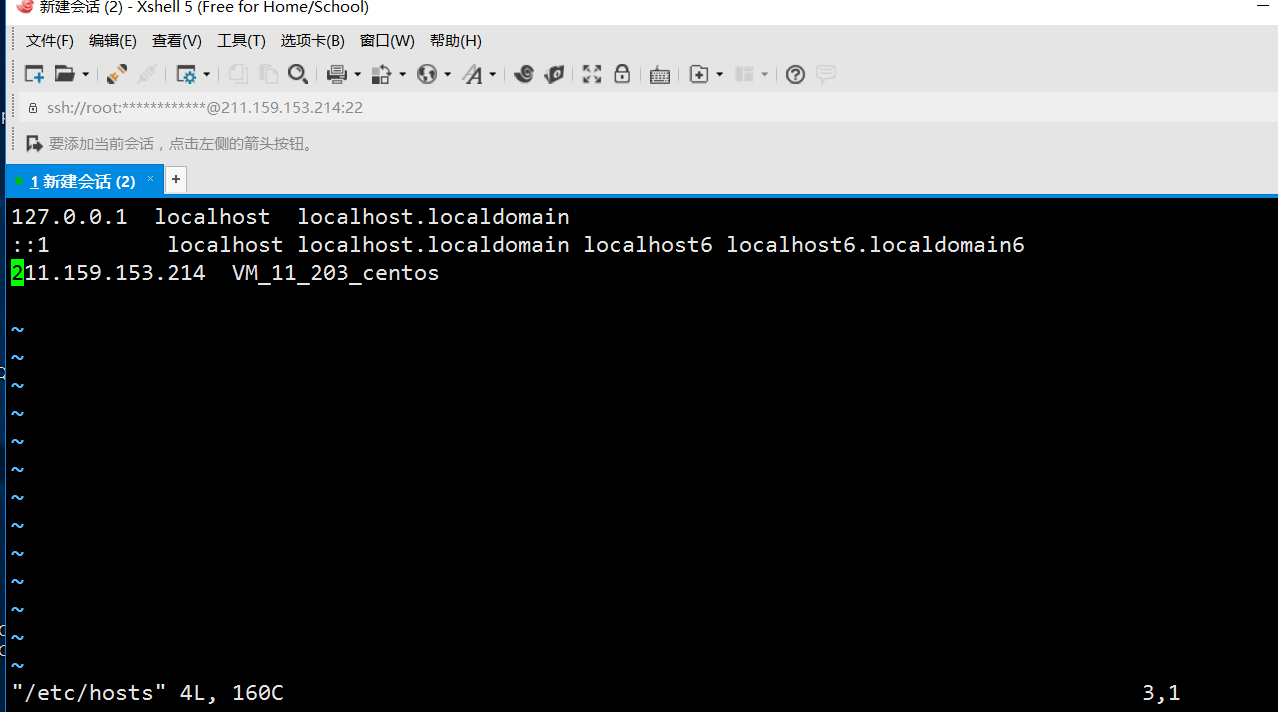
然后输入 reboot 重启机器
配置 ssh 免密码登录
[root@VM_11_203_centos ~]# ssh 211.159.153.214
The authenticity of host '211.159.153.214 (211.159.153.214)' can't be established.
ECDSA key fingerprint is 22:49:b2:5c:7c:8f:73:56:89:29:8a:bd:56:49:74:66.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '211.159.153.214' (ECDSA) to the list of known hosts.
[email protected]'s password:
这里我们要输入密码特别的不方便,所以要取消。
输入 ssh-keygen -t rsa 然后四个回车
[root@VM_11_203_centos ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
e4:7d:24:39:20:e1:27:07:3b:4c:8d:b0:3d:f6:4f:13 root@VM_11_203_centos
The key's randomart image is:
+--[ RSA 2048]----+
| ..=+. |
| *.+.. . |
| . X + E . |
| . X . = |
| S + . |
| o o |
| . |
| |
| |
+-----------------+
然后复制密钥到本机
[root@VM_11_203_centos ~]# ssh-copy-id 211.159.153.214
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@211.159.153.214's password:
[root@VM_11_203_centos ~]# ssh 211.159.153.214
Last login: Thu Mar 16 17:26:00 2017 from 218.21.34.74
因为 hadoop 是 java 写的,所以在这里要 配置 JAVA 的环境变量,
先创建几个目录,用来存放后面的文件
[root@VM_11_203_centos ~]# cd /home
[root@VM_11_203_centos home]# ls
[root@VM_11_203_centos home]# mkdir softwares
[root@VM_11_203_centos home]# mkdir tools
[root@VM_11_203_centos home]# mkdir datas
[root@VM_11_203_centos home]# cd tools/
看一下系统是否安装了 java
[root@VM_11_203_centos tools]# rpm -qa|grep jdk
[root@VM_11_203_centos tools]# rpm -qa|grep java
输入这两句啥都没有说明系统没有安装 jdk,
开始安装 jdk ,通过 yum 来安装一个文件上传插件。[root@VM_11_203_centos tools]# yum install lrzsz – y
最后出现Complete!,说明安装成功。
然后上传 JDK[root@VM_11_203_centos tools]#rz
如果上传过慢,也可以用 Xsell 自带的文件上传功能上传文件,将我们的 hadoop-2.7.1.tar.gz 和 jdk-7u67-linux-x64.tar.gz 一起上传上去到我们新建的 tools 目录。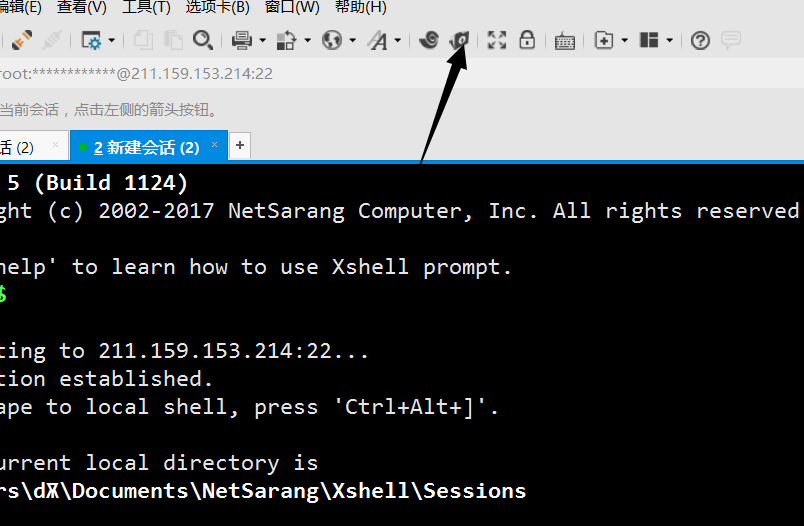
开始用 tar 命令解压我们的文件[root@VM_11_203_centos tools]# tar -zxf jdk-7u67-linux-x64.tar.gz -C ../softwares/
解压完毕后,开始配置环境变量
这里不知道 jdk 的目录层级,可以使用 pwd 进行查看。[root@VM_11_203_centos jdk1.7.0_67]# pwd/home/softwares/jdk1.7.0_67
开始修改配置文件[root@VM_11_203_centos jdk1.7.0_67]# vim /etc/profile
在 profile 文件后面追加
export JAVA_HOME=/home/softwares/jdk1.7.0_67
export PATH=$PATH:$JAVA_HOME/bin
使配置生效[root@VM_11_203_centos jdk1.7.0_67]# source /etc/profile
测试环境变量,输入[root@VM_11_203_centos jdk1.7.0_67]# java – version
出现
java version "1.7.0_67"
Java(TM) SE Runtime Environment (build 1.7.0_67-b01)
Java HotSpot(TM) 64-Bit Server VM (build 24.65-b04, mixed mode)
说明我们的配置生效了,环境变量没有配错。
然后开始安装 hadoop
解压我们一开始上传的 hadoop 文件[root@VM_11_203_centos tools]# tar -zxf hadoop-2.7.1.tar.gz -C ../softwares/
解压完成后,进入我们的 hadoop 目录,来对其进行配置
[root@VM_11_203_centos tools]# cd ../softwares/hadoop-2.7.1/
[root@VM_11_203_centos hadoop-2.7.1]# cd etc/hadoop/
配置 hadoop-env.sh ,主要是配置 java 的环境变量 [root@VM_11_203_centos hadoop-2.7.1]# vim hadoop-env.sh
修改 export JAVA_HOME=${JAVA_HOME}为 export JAVA_HOME=/home/softwares/jdk1.7.0_67
开始配置 core-site.xml
回到 hadoop 主目录然后创建 data 目录,来存放我们 hadoop 的缓存目录。[root@VM_11_203_centos hadoop-2.7.1]# mkdir data
[root@VM_11_203_centos hadoop-2.7.1]# cd data
[root@VM_11_203_centos data]# mkdir tmp
[root@VM_11_203_centos data]# cd tmp
[root@VM_11_203_centos hadoop-2.7.1]# cd etc/hadoop/
[root@VM_11_203_centos hadoop]# vim core-site.xml
在 configuration 标签下加入(一下文件配置都是在次标签下加入的)
<name>fs.defaultFs</name>
<value>hdfs://211.159.153.214:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/softwares/hadoop-2.7.1/data/tmp</value>
</property>
开始配置 hdfs-site.xml (设置备份数, hadoop 默认是三份,由于我们是伪分布式,所以一份就够了)
<name>dfs.replication</name>
<value>1</value>
然后开始格式化文件系统
[root@VM_11_203_centos hadoop-2.7.1]# bin/hdfs namenode – format
看到 successfully formatted 说明格式化成功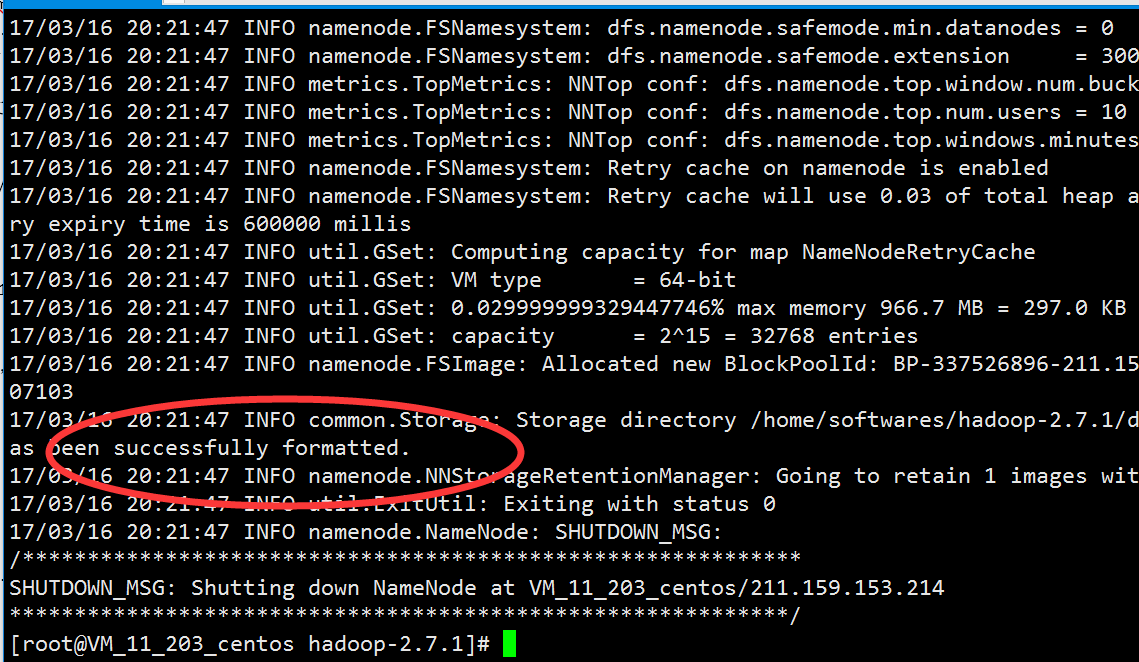
然后启动我们的进程[root@VM_11_203_centos hadoop-2.7.1]# sbin/start-dfs.sh
遇到选项就输入 yes
查看进程
[root@VM_11_203_centos hadoop-2.7.1]# jps
14262 NameNode
14385 DataNode
14601 SecondaryNameNode
14724 Jps
出现上面的说明启动成功
若启动报错改变如下配置[root@VM_11_203_centos hadoop-2.7.1]# vim etc/hadoop/core-site.xml
在 core-site.xml 加入
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
然后重新启动就发现启动成功了。
在浏览器输入http://211.159.153.214:50070/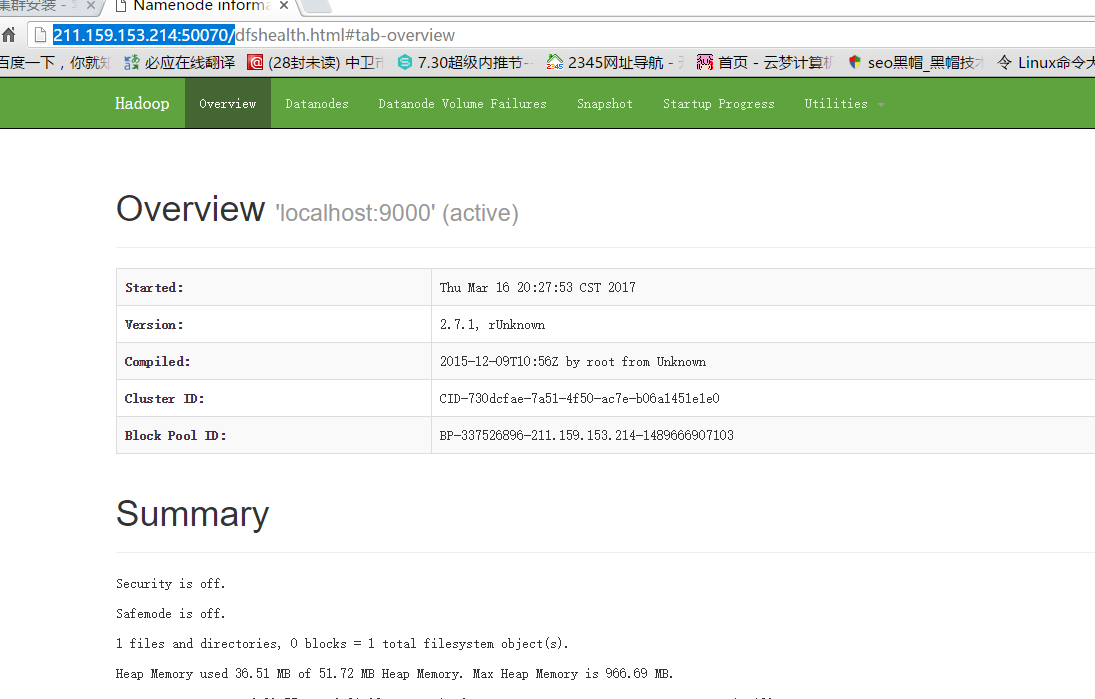
说明打开成功了。
安装 yarn , hadoop 中的资源调度。
然后修改 hadoop 目录下的 mapred-site.xml.template (主要是让咋们的 mapreduce 服从 yarn 的调度)
[root@VM_11_203_centos hadoop-2.7.1]# mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[root@VM_11_203_centos hadoop-2.7.1]# vim etc/hadoop/mapred-site.xml
加入一下配置
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置 yarn-site.xml (配置 mapreduce 去数据的方式)
[root@VM_11_203_centos hadoop-2.7.1]# vim etc/hadoop/mapred-site.xml
[root@VM_11_203_centos hadoop-2.7.1]# vim etc/hadoop/yarn-site.xml
增加如下配置
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<!-- Site specific YARN configuration properties -->
</property>
启动[root@VM_11_203_centos hadoop-2.7.1]# sbin/start-yarn.sh
jps 看一下
14262 NameNode
15976 NodeManager
14385 DataNode
15884 ResourceManager
14601 SecondaryNameNode
16120 Jps
五个进程都启动成功,说明咋们的配置正确,启动中有什么错误请查看日志文件。
在浏览器输入
http://211.159.153.214:8088/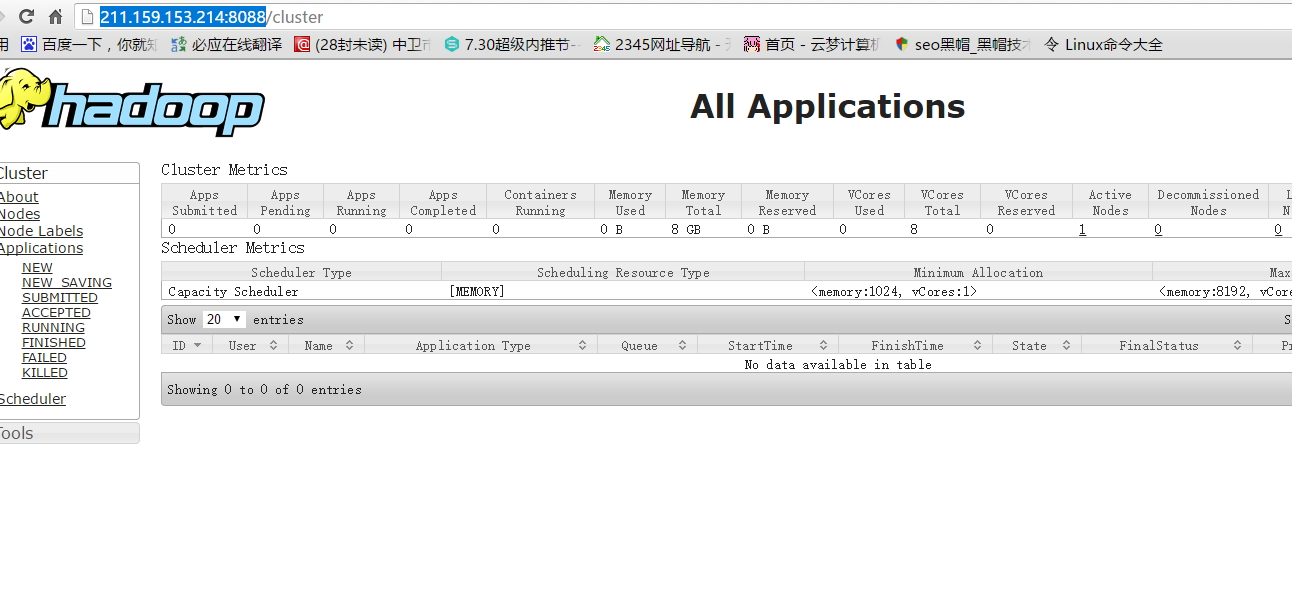
说明我们整个 hadoop 配置成功。
开始测试(用 hadoop 做一下词频统计)
进入 data 目录下
[root@VM_11_203_centos hadoop-2.7.1]# cd /home/data
[root@VM_11_203_centos data]# touch words
[root@VM_11_203_centos data]# vim words
Hello a
Hello b
统计单词出现的个数。
开始上传文件
[root@VM_11_203_centos data]# cd /home/softwares/hadoop-2.7.1/
开始上传文件[root@VM_11_203_centos hadoop-2.7.1]# bin/hadoop fs -put /home/data/words /words
上传成功后输入命令开始统计[root@VM_11_203_centos hadoop-2.7.1]#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /words /out
然后查看结果
[root@VM_11_203_centos hadoop-2.7.1]# bin/hadoop fs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2017-3-16 21:05 /out
drwx------ - root supergroup 0 2017-3-16 21:02 /tmp
-rw-r--r-- 1 root supergroup 16 2017-3-16 20:51 /words
[root@VM_11_203_centos hadoop-2.7.1]# bin/hadoop fs -ls /out
Found 2 items
-rw-r--r-- 1 root supergroup 0 2017-3-16 21:05 /out/_SUCCESS
-rw-r--r-- 1 root supergroup 16 2017-3-16 21:04 /out/part-r-00000
开始查看结果
root@VM_11_203_centos hadoop-2.7.1]# bin/hadoop fs -cat /out/part-r-00000
结果如下
Hello 2
a 1
b 1
查询完成;
工作过程
hdfs 原始数据:hello ahello b
map 阶段:
输入数据:<0,"hello a"><8,"hello b">
输出数据:
map(key,value,context) {
String line = value; //hello a
String[] words = value.split("\t");
for(String word : words) {
//hello
// a
// hello
// b
context.write(word,1);
}
}
< hello,1>
< a,1>
< hello,1>
< b,1>
reduce 阶段(分组排序):
输入数据:
< a,1>
< b,1>
< hello,{1,1}>
输出数据:
reduce(key,value,context) {
int sum = 0;
String word = key;
for(int i : value) {
sum += i;
}
context.write(word,sum);
}
本文首发腾云阁并已获得授权
目前尚无回复