推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide
这是一个创建于 2979 天前的主题,其中的信息可能已经有所发展或是发生改变。
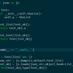
import re
a='abcabc'
b=re.search( r '(\d)abc(?(1)\d|abc)', a )
print(b)
#为何匹配失败? a='3abcabc'也是如此!
查了下(?(1)\d|abc) 的意思:如果编号为 1 的组匹配到字符,则需要匹配\d ,否则需要匹配 abc.
这里的 1 匹配到字符是指 c 后面匹配到字符呢还是 a 前面匹配到数字字符?
a='abcabc'
b=re.search( r '(\d)abc(?(1)\d|abc)', a )
print(b)
#为何匹配失败? a='3abcabc'也是如此!
查了下(?(1)\d|abc) 的意思:如果编号为 1 的组匹配到字符,则需要匹配\d ,否则需要匹配 abc.
这里的 1 匹配到字符是指 c 后面匹配到字符呢还是 a 前面匹配到数字字符?
 |
1
slideclick 2016-11-14 17:54:43 +08:00
a='3abc3abc'成功
答案: 1 是 a 前面匹配到数字字符 |
 |
2
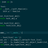
icris 2016-11-14 17:59:59 +08:00 看后面的判断,你可能需要的表达式是 r'(\d)?abc(?(1)\d|abc)' ,你的表达式只有编号为 1 的组匹配到字符的情况,没有匹配不到的情况。
··· >>> re.search(r'(\d)?abc(?(1)\d|abc)', 'abcabc').group() 'abcabc' ··· |
 |
3
explist OP @slideclick
从概念上说, 1 确实是对第一个分组的匹配文本的引用。 这样问更准确:后面管道符 | 的左右两个子表达式选择时的判断依据是什么?是最前面的分组是否成功匹配(\d),还是 c 字符后面是否成功匹配( 1 )? 虽然最前面有数字字符(成功匹配了分组),但 c 后面仍然可能没有数字字符 |
|
6
explist OP '2abc1abc' : 这也能匹配成功?!!!
难道( 1 )是引用的'\d'本身,而不是对其匹配结果的引用? 这与 \1 明显不同 |
|
7
explist OP |
 |
8
DiamondbacK 2016-11-14 19:14:44 +08:00 (1) 是判断 (\d) 是否匹配成功;
是,则接着尝试匹配 \d ,这跟捕获组 1 已经没有关系了,就是单纯的 \d ; 否,则尝试匹配 abc ,这就没有意义了,因为既然 (\d) 没有匹配到,那后面再怎么尝试,整个匹配式都是不匹配的,所以应该是 2 楼说的,正则表达式写错了,不是 (\d) 而是 (\d)?,它能匹配任何字符。 |
|
9
DiamondbacK 2016-11-14 19:21:35 +08:00
更正,原表达式中的 (\d) 一旦匹配失败,就没有后面的尝试了,因为一个正常的正则引擎已经可以判断在这个位置整个表达式匹配都失败了。
|

 |
11
chaleaoch 2016-11-14 21:42:14 +08:00 |
|
12
explist OP If Clause (?(1)\d|abc)
Evaluate the condition below and proceed accordingly (1) checks whether the 1st capturing group matched when it was last attempted If condition is met, match the following regex \d \d matches a digit (equal to [0-9]) Else match the following regex abc abc matches the characters abc literally (case sensitive) |
|
14
explist OP google 翻译:
如果条款(?( 1 )\ d | abc ) 评估以下条件并相应地进行 ( 1 )检查第一捕获组是否在最后一次尝试时匹配 如果条件满足,匹配以下正则表达式\ d \ d 匹配数字(等于[0-9]) 否则匹配以下正则表达式 abc abc 匹配字符 abc 字面上(区分大小写) |
|
16
explist OP 这个有点奇怪,会回退去匹配
re.search(r'(\d)?abc(?(1)\d|abc)', '2abcabc') 结果为:‘ abcabc' 当经过(1)判断,进行第 2 个\d 匹配,失败后居然回到第一个 a 处重新开始又一次的正则式匹配,难道前面的匹配只有分组消耗字符??? |
 |
17
mingyun 2016-11-14 23:42:23 +08:00
|
|
18
DiamondbacK 2016-11-14 23:53:03 +08:00
@explist
并没有退回,条件表达式 (?ifthen|else) 匹配失败所以自然没有消耗字符。 |
|
19
explist OP @DiamondbacK 那也应该从第 2 个 a 开始,不是吗
|
|
20
DiamondbacK 2016-11-15 00:18:25 +08:00 @explist
因为条件表达式匹配失败,所以整个正则式在索引 0 匹配失败,所以挪到索引 1 进行匹配。 |
 |
21
Shawn2ex 2016-11-15 09:09:02 +08:00 https://jex.im/regulex 正则表达式可视化
|