
这是一个创建于 3504 天前的主题,其中的信息可能已经有所发展或是发生改变。
Cgroup - Linux 的网络资源隔离
Hi ,我是 Zorro 。这是我的微博地址,如果你有兴趣,可以来关注我呦。
这是我的博客地址,我会不定期在这里更新文章,如有谬误,欢迎随时指正。
另外,我的其他联系方式:
Email: [email protected]
QQ: 30007147
由于字数限制,你在 V2EX 上直接看到的这个文章并不完整,完整版请移步我的博客。
本文不会涉及一些网络基础知识的讲解以及 iproute2 相关命令的使用的讲解,建议如果想要更好理解本文,之前应该对网络知识、 tc 命令和LARTC的文档有一定了解。如果本文中有什么知识点让不够清楚,可以结合 LARTC 文档一起服用。
想要直接上手配置 cgroup 的网络资源隔离的人,可以直接看本文倒数第二部分:使用 cgroup 限制网络流量。
今天我们来谈谈:
Linux 的网络资源隔离
如果说 Linux 内核的 cgroup 算是个新技术的话,那么它的网络资源隔离部分的实现算是个不折不扣的老技术了。实际上是先有的网络资源的隔离技术,才有的 cgroup 。或者说是先有的网络资源的隔离才有的 2.4 、 2.6 版本的 Linux 内核,而现在的最主流的内核版本应该是 3.10 了(考虑到 android 手机的出货量,你公司那几千几万台服务器真的算是个零头对吧?)。好吧, Linux 早在内核 2.2 版本就已经引入了网络 QoS 的机制,并且网络资源的隔离功能只是其所实现功能的一部分而已。无论如何, cgroup 并没有再重新搞一套网络资源隔离的实现,而是直接使用了 Linux 的 iproute2 的 traffic control ( tc )功能。实际上网络资源隔离的文档真的不用我再多写什么了,我最亲爱的前同事+朋友+导师—— johnbull 同志早已经在 2003 年的非典期间就因为无聊而完成了非常高质量的相关技术文档翻译工作,将这方面最权威的 LARTC ( Linux Advanced Routing & Traffic Control )文档翻译成了中文版。
曾经 chinaunix 的资深版主 johnbull 同志现在在新浪微博工作,所以经常在微博出没,如果对以上文档有兴趣和疑问的人可以直接去找他对质,传送门在此。
其实原则上说,本技术文章已经讲完了,但是为了不让大家有种上当受骗的感觉,我觉得我还是有必要从 cgroup 的角度再来讲讲 tc ,也算是对 TC 近几年发展做一个补充。
什么是队列规则
tc 命令引入了一系列概念,其中我们最需要先理解的就是队列规则。它的英文名字叫做 queueing discipline ,在 tc 命令中也叫 qdisc ,或者直接简写为 qd 。我们先来看看它,有个感性的认识:
在我的虚拟机的 centos7 中,它是这样的:
[root@localhost Desktop]# tc qd ls
qdisc pfifo_fast 0: dev eno16777736 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
在我的台式机上装的 archlinux (更新到了当前最新版的 4.3.3 内核)以及 fedora 23 上是这样的:
[root@zorrozou-pc0 zorro]# tc qd ls
qdisc noqueue 0: dev lo root refcnt 2
qdisc fq_codel 0: dev enp2s0 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms ecn
在公司的服务器上是这样的:
[root@tencent64 /data/home/zorrozou]# tc qd ls
qdisc mq 0: dev eth1 root
qdisc pfifo_fast 0: dev tun0 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: dev veth213_121_54 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: dev veth213_135_194 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: dev veth213_123_25 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: dev veth213_121_112 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: dev veth213_123_207 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: dev veth213_123_82 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: dev veth213_117_111 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
从以上输出大家应该可以判断出来,这个所谓的 qdisc 是针对网卡的,每有一个网卡就会有一个 qdisc 。而且如果你用过 ip 命令并且比较细心的话,应该早就注意到 ip ad sh 的时候也会出现相关的信息:
[zorro@zorrozou-pc0 ~]$ ip ad sh
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp2s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 34:64:a9:15:a2:17 brd ff:ff:ff:ff:ff:ff
inet 10.18.73.69/24 brd 10.18.73.255 scope global dynamic enp2s0
valid_lft 28283sec preferred_lft 28283sec
inet6 fe80::3664:a9ff:fe15:a217/64 scope link
valid_lft forever preferred_lft forever
虽然看上去有些高深莫测,但是 qdisc 其实是个挺简单的概念,它就是它字面的意思:队列规则,或者叫做排队规则。我们都知道,网络数据都是被封装成一个一个的数据包进行传输的。如果网卡相当于数据包要出发的大门的话,那么 qdisc 无非就是规定了这些包在出发前如果需要排队的话该怎么排。我们先拿这个叫做 pfifo_fast 的队列规则来举例子描述一下吧,这个 qdisc 实现了一个以数据包( package )为单位的 fifo 队列,实际上可以认为是实现了三个队列(叫做 bands ),给每个队列定了一个优先级,以实现带优先级的排队规则。我们举个现实中的例子再来说明一下,大家都应该有去公交车站排队的经验吧?(神马?作为中国人你从来不排队?)无论怎样,我们假定你是排队的。每来一次公交车,就相当于网卡处理一次队列中的数据包,而每个人就是一个数据包。那么我们一般人到了公交站,如果发现前面已经排了一队人,此时根据 fifo ( first in first out )的规则,我们会排在队列尾部。如果来车了,就从队列头的人先上车,车满就走,没上完的人继续等待。但是我们也知道,如果此时来了个孕妇或者大爷大娘等一些按照我们社会美德要求应该让他们优先的乘客的话,这些人应该有权利优先上车。那么怎么办呢?我们公交站台的解决办法一般是直接让他们去队列头插队就好,但是如果空间允许的话,我们可以考虑多建立一个队列。让这些可以优先上车的人排一个队,正常人排一个队,车来了先上优先级比较高的那个队列中的人,他们都上完了再让一般队列中上人车。这样就实现了一个简单的队列规则,大家根据自己的情况去选择排队就好了。
pfifo_fast 实现了一个类似上述描述的队列规则,区别是它实现了 3 个优先级的队列( bands ),每个数据包来了都根据自己的情况选择一个 band 进行排队,每个 band 都是 fifo 方式处理数据包。它总是先处理优先级最高的 band ,直到没有数据包了再处理下一个优先级的 band ,直到三个都处理完,或者本次处理不完,继续等着下次处理。那么数据包按什么规则进行选择自己该进入哪个 band 呢?这就是后面显示的priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1的含义,这个字段描述了一个 priomap ,可以理解为优先级位图,后面的 16 个不同的位,表示相关制如果为真时的数据包应该进入哪个队列,一共有 0 、 1 、 2 三个队列。而这个 16 位的位图标记,针对的就是我们 IP 报头中的 TOS 字段。根据 IP 协议的定义我们知道, TOS 字段 8 位中的 4 位分别是用来标示最小延时、最大吞吐量、最大可靠性和最小消费四种数据包类型的, IP 协议原则上会根据这些标示的不同以不同的 QOS 对上层交付不同的服务质量。这些不同的搭配理论上一躬有 16 种,这就是 priomap 所映射的优先级的概念。
如果你对 TOS 的概念还不熟悉,请自行补充网络相关基础知识。推荐的教材是《 TCP / IP 详解卷 1 》。
pfifo_fast 队列处理过程如图所示:
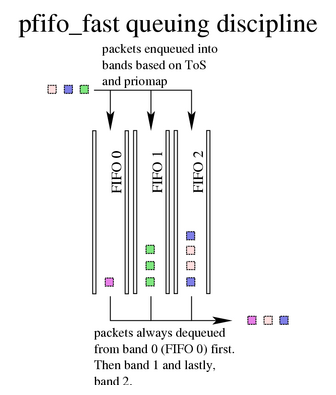
pfifo_fast 一般情况下是内核对网卡默认选择的 qdisc ,它虽然提供了简单的优先级分类的支持,但是并没有提供可供修改的参数,就是说默认的优先级分类设置不能更改,也没有提供相关限速的功能。这个队列规则在一般情况下工作的都很稳定,但是最近 Linux 已经开始放弃使用这个 qd 作为默认的队列规则而改用一种叫做 fq_codel 的 qdisc 了。主要原因是,由于移动互联网的广泛应用,一种叫做 Bufferbloat 的现象影响越来越大了。
Bufferbloat
Bufferbloat 现象最初是用来形容在一个分组交换网络上,路由器为防止丢包,往往 buffer 缓冲区都会实现的很大,但是这种过大的 fifo 缓冲区可能导致数据包 buffer 中等待时间过长而导致很多问题(后面会有分析)。再加上网络上 TCP 的拥塞控制算法的影响,以及很多商业操作系统甚至并不实现拥塞控制,导致数据传输质量抖动很大(全局同步),甚至于达到服务不可用的状态。
后来我们发现, Bufferbloat 这种现象比较广泛的存在在各种系统中,只要系统中使用了类似队列、缓存等机制的时候,就在某些极端状态下出现这种类似雪崩的现象。我们简要描述一下这个状态。我们先简单构建一个试用 buffer 的场景,如图所示:
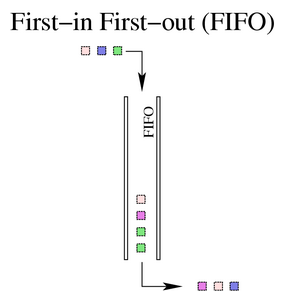
根据图的描述,我们假定这个简单的 fifo 就是我们要的 buffer 系统,它在两个处理过程之间充当缓冲区的作用。每个请求从队列的上面进入排队,然后依次被下面的处理程序处理。大家应该知道 buffer 的作用:一个缓冲器的作用主要是弥补两个处理系统之间的速度差异,能够在一定程度的请求速度抖动的时候缓解处理速度慢而导致的请求失败。假设,后段处理请求的速度为 1000 个 /s ,每个请求平均长度为 100byte ,队列长队为 1Mbyte ,此时,如果请求突然增加到了 2000 个 /s ,那么这个压力直接压给后端是处理不过来的,每秒钟就要丢弃 1000 个包。所以我们使用一个 buffer ,可以让这一秒钟来的请求先处理 1000 个,然后有 1000 个排在队列中,下一秒处理。只要来的请求的抖动范围还算正常,我们的系统将会工作的良好,没有失败的请求。
对于一般的系统,我们发送的请求都是有延时要求的,鉴于我们的系统每秒钟可以处理 1000 个请求,所以每个请求的处理时间平均为 1ms 。而我们的系统基于目前的处理时间,对外提供了 100ms 的延时 SLA ,就是说,后端系统保证每个请求的处理时间是 100ms 以内,这已经很大了,是正常情况的 100 倍。于是前端的请求方,会根据后端给出的 SLA 在程序中设定一个超时时间,在这个例子中就应该是 100ms ,这可能意味着,程度调用后端系统,如果等待 100ms 还没有结果,那么将重试一次或者几次不等,之后应该会返回失败。场景就是这样一个场景,那么我们来看看究竟什么是 bufferbloat ?
假定现在因为业务问题,比如上线了一个秒杀的抢购活动,导致从前端发来的请求一瞬间远远大于后端的处理能力。比如,一秒钟内产生了 10000 次请求,这一万次请求都会立即进入队列中等待后端处理。因为后端的处理速度是 1000 次每秒,所以可以想像,当前在队列中的最后一个数据包至少要等待 9 秒钟才能处理到。实际上根本处理不到这最后一个请求,由于我们设置了 100ms 的超时时间,那么调用方将很快因为发现 100ms 中没有返回而重试一次,于是又来了将近 10000 个请求。这些请求都积压在了队列中,还没交给后端进行处理,如果交给了后端处理,后端肯定会因为压力变大处理变慢,而导致处理事件超过 100ms 的 SLA ,会在超时之后告诉前端本次请求失败(如果是这样实现的话),而现在由于队列的存在,并大量的积压请求,导致调用方不能明确的得知失败。所以一般都是等待至少一次超时重试一次再失败,当然也有很多情况会重试个 4 , 5 次也说不定。
无论如何,这突发的 10000 个请求的流量来了之后,如果平均每个请求 100 字节,这 1M 的缓冲区就已经满了,后续再有任何请求来,都会排在队列末尾,一直等到前面的请求处理完再处理这个请求,而此时因为整体处理时间很慢,要将此队列中的全部请求处理完需要 9 秒钟,无论如何,这个请求都已经超时失败了。这个时候后端服务一直满载的处理队列中的请求,而前端还不断有新请求源源不断的放进队列,但是由于超时,前端所有请求都是返回失败,后端所处理的请求也都是等待时间超过 100ms 的无效的请求,即使成功返回结果给前端,前端也不会要了。效果就是后端很忙,而整体服务却是不可用的。此时哪怕请求平均速度恢复到 1000 个每秒,服务也无法恢复。这就是一个典型的 bufferbloat 场景。
于是我们可以考虑一下这个场景会发生在什么地方?比如 buffer 比较大的路由器,由于 tcp 的流量控制和重试机制导致网络质量的抖动;比如一个后端的数据库系统为了能够承载更大的吞吐量而添加了队列系统;比如 io 调度;比如网卡调度;只要是大 buffer 的场景都会可能产生类似的问题。那么该如何解决这个问题呢?于是主动队列管理算法应运而出了。
CoDel 算法
CoDel 算法是另一种 AQM 算法,其全称是 Controlled Delay 算法。是由 Van Jacobson 和 Kathleen Nichols 在 2012 年实现的。具体描述参见Controlling Queue Delay。 CoDel 采用了另外一种角度来观察队列满载的问题,其出发点并不是对队列长度进行控制,而是对队列中的数据包的驻留时间进行控制。事实上如果我们将管理方式由队列长度控制变成等待时间控制的时候, bufferbloat 就可以彻底解决了,这也是更先进的 AQM 算法所用的方式。我们仔细观察 bufferbloat 问题,会发现,引起这个问题的重要原因就是数据包在队列中的驻留时间过长,超过了有效的处理时间( SLA 定义的时间或者重试时间),导致处理到的数据包都已经超时。
首先我们根据我们的业务设计,确定出请求在队列中正常情况应该驻留多久。我们还是假定这样一种场景,根上面 bufferbloat 中描述的例子差不多:后端处理速度是 1000 次每秒,就是 1ms 可以处理一个请求,而队列平均长度一般为 5 ,就是说一个新请求进入队列之后,发现前面还有 5 个请求在等待,那么这个新请求的处理时间大约为 6ms (在队列中等待 5ms )。那么请求在队列中的驻留时间正常情况下基本为 5ms 。而我们服务的 SLA 确定的时间是 100ms (由诸如服务超时时间或者所在网络的最大 RTT 时间等条件确定),就是说,服务应确保在 100ms 内给出反馈,这个时间叫做 interval time ,如果超过这个时间应该返回失败。针对这样的情况,我们可以根据请求驻留时间的情况来描述一个动态长度的队列,当一个请求入队之后,对其驻留时间( sojourn time )进行追踪,以正常的情况作为其目标驻留时间( target time ),在这个例子中是 5ms ,就是说一般情况下,我们期望请求在队列中的驻留时间不高于 5ms 。由于业务的超时时间或者说我们提供的 SLA 处理时间是 100ms ,所以,在这个队列中驻留超过 100ms 的请求都应该丢弃(从队列头开始),因为即使处理完成它们也没有意义了。丢弃将持续到队列中的请求等待时间回到理想的 target time 为止,并且队列长度整体不大于队列容量上限。这样就根据驻留时间维持了一个动态长度的队列,这个队列中的所有请求理论上都应该等待 100ms 以内,要么被正常处理掉,要么被丢弃。这就是 CoDel 算法的基本思路。
为了有助于大家理解,我们再详细一点描述一下这个算法的处理过程:
CoDel 算法对队列状态维护一个状态机,进行队列 dequeue 处理的时候,先判检查队列头请求的驻留时间( sojourn time )是否大于 target time ,如果不大于 target time ,就直接 dequeue ;如果大于( target time )的请求维持了 interval time 这么长的时间,则队列应该进入 dropping 状态开始丢包。这种丢包状态将可能维持一段时间,这段时间的长度将根据情况而定(驻留时间一直处在 target 以上,并且下一个包丢弃的时间采用逆平方根运算( inverse-square-root ),公式为:
t (第一次取 now ,以后取上次的值) + interval / sqrt(count))
count 的取值为丢弃包的个数,如果 count 大于 2 则 count = count - 2 ,其他情况 count 取值为 1 。直到驻留时间小于 target time ,就退出 dropping 状态。
算法的伪代码描述参见这里。
我们之所以要如此详细的描述 bufferbloat 问题以及其解决方案,尤其是 CoDel 算法,原因是其不仅仅被用在网络的分组交换和路由的处理上。除了 TC 的队列规则外, CoDel 当前还被用在了内核 TCP 协议栈的拥塞控制中,并且 rabbitmq 也已经把这个算法应用于消息队列的延时控制了,参见。这个算法在数据中心的应用场景下,是一个非常好的解决队列阻塞的方案。
了解了以上知识之后,我们来看一下再 Linux 上如何配置一个 CoDel 的队列规则,我们刚才已经将队列规则改为 RED 了,此时如果要将其改为 CoDel ,需要先删除 RED 的队列规则,再添加新的队列规则:
[root@zorrozou-pc0 zorro]# tc qd del dev enp2s0 root
[root@zorrozou-pc0 zorro]# tc qdisc add dev enp2s0 root codel limit 100 target 4ms interval 30ms ecn
[root@zorrozou-pc0 zorro]# tc qd ls dev enp2s0
qdisc codel 8002: root refcnt 2 limit 100p target 4.0ms interval 30.0ms ecn
[root@zorrozou-pc0 zorro]# tc -s qd ls dev enp2s0
qdisc codel 8002: root refcnt 2 limit 100p target 4.0ms interval 30.0ms ecn
Sent 5546 bytes 39 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
count 0 lastcount 0 ldelay 0us drop_next 0us
maxpacket 0 ecn_mark 0 drop_overlimit 0
tc 的-s 参数相信你已经明白什么意思了。来说一下 codel 队列规则的相关参数:
limit:队列长度上限,如果超过这个长度,新来的数据包将被直接丢弃。单位为字节数,默认值为 1000.
target && interval:这两个参数相信大家已经明白是什么意思了,根据自己的场景进行配置就好了。
ecn && noecn:这个参数的含义根 RED 中的一样,默认是开启的 ecn 方式通知源端,不丢包。
大家也可以直接使用 codel 规则的默认参数,就是其他参数都省略即可。我们来看看什么效果:
[root@zorrozou-pc0 zorro]# tc qd del dev enp2s0 root
[root@zorrozou-pc0 zorro]# tc qdisc add dev enp2s0 root codel
[root@zorrozou-pc0 zorro]# tc -s qd ls dev enp2s0
qdisc codel 8003: root refcnt 2 limit 1000p target 5.0ms interval 100.0ms
Sent 8613 bytes 33 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
count 0 lastcount 0 ldelay 0us drop_next 0us
maxpacket 0 ecn_mark 0 drop_overlimit 0
使用 cgroup 限制网络流量
最后,我们要来看看如何在 cgroup 的场景下对网络资源进行隔离了。实际上跟我们上面讲的 HTB 的例子类似,区别是,上面的例子是通过端口分类,而现在需要通过 cgroup 进行分类。我们还是通过一个例子来说明一下场景,并实现其功能:我们假定现在有两个 cgroup ,一个叫 jerry ,另一个叫 zorro 。我们现在需要给 jerry 组中运行的网络程序限制带宽为 10mbit , zorro 组的网路资源占用为 20mbit ,总带宽为 100mbit ,并且不允许借用( ceil )网络资源。那么配置思路是这样:
我们的配置环境是一台 centos7 的虚拟机,首先,我们在这个服务器上运行一个 apache 的 http 服务,并发布了一个 1G 的数据文件作为测试文件,并在不限速的情况下对齐进行下载速度测试,结果为 100MBps ,注意这里的速度是 byte 而不是 bit :
zorrozou-nb:~ zorro$ curl -O http://192.168.139.136/file
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1024M 100 1024M 0 0 101M 0 0:00:10 0:00:10 --:--:-- 100M
之后我们在 centos7(192.168.139.136)上实现三个分类,一个带宽限制 10m 给 jerry ,另一个 20m 给 zorro ,还有一个为 30m 用作 default ,总带宽 100m ,剩余的资源给以后可能新加入的 cgroup 来分配,于是先建立相关的规则和分类:
[root@localhost Desktop]# tc qd add dev eno16777736 root handle 1: htb default 100
[root@localhost Desktop]# tc cl add dev eno16777736 parent 1: classid 1:1 htb rate 100mbit burst 20k
[root@localhost Desktop]# tc cl add dev eno16777736 parent 1:1 classid 1:10 htb rate 10mbit burst 20k
[root@localhost Desktop]# tc cl add dev eno16777736 parent 1:1 classid 1:20 htb rate 20mbit burst 20k
[root@localhost Desktop]# tc cl add dev eno16777736 parent 1:1 classid 1:100 htb rate 30mbit burst 20k
[root@localhost Desktop]# tc qd add dev eno16777736 parent 1:10 handle 10: fq_codel
[root@localhost Desktop]# tc qd add dev eno16777736 parent 1:20 handle 20: fq_codel
[root@localhost Desktop]# tc qd add dev eno16777736 parent 1:100 handle 100: fq_codel
建立完分类之后,由于默认情况都要走 1:100 的分类,所以限速应该是 30mbit ,验证一下:
zorrozou-nb:~ zorro$ curl -O http://192.168.139.136/file
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 1024M 0 3484k 0 0 3452k 0 0:05:03 0:00:01 0:05:02 3452k
当前速度为 3452kB 左右,大概为 30mbit ,符合预期。之后将我们的 http 服务放到 zorro 组中看看效果,当然是首先建立相关 cgroup 以及相关配置:
[root@localhost Desktop]# ls /sys/fs/cgroup/net_cls/
cgroup.clone_children cgroup.event_control cgroup.procs cgroup.sane_behavior net_cls.classid notify_on_release release_agent tasks
[root@localhost Desktop]# mkdir /sys/fs/cgroup/net_cls/zorro
[root@localhost Desktop]# mkdir /sys/fs/cgroup/net_cls/jerry
[root@localhost Desktop]# ls /sys/fs/cgroup/net_cls/{zorro,jerry}
/sys/fs/cgroup/net_cls/jerry:
cgroup.clone_children cgroup.event_control cgroup.procs net_cls.classid notify_on_release tasks
/sys/fs/cgroup/net_cls/zorro:
cgroup.clone_children cgroup.event_control cgroup.procs net_cls.classid notify_on_release tasks
建立完毕之后分别配置相关的 cgroup ,将对应 cgroup 产生的数据包对应到相应的分类中,配置方法:
[root@localhost Desktop]# echo 0x00010100 > /sys/fs/cgroup/net_cls/net_cls.classid
[root@localhost Desktop]# echo 0x00010010 > /sys/fs/cgroup/net_cls / jerry/net_cls.classid
[root@localhost Desktop]# echo 0x00010020 > /sys/fs/cgroup/net_cls / zorro/net_cls.classid
[root@localhost Desktop]# tc fi add dev eno16777736 parent 1: protocol ip prio 1 handle 1: cgroup
这里的 tc 命令是对 filter 进行操作,这里我们使用了 cgroup 过滤器,来实现将 cgroup 的数据包送到 1:0 分类中,细节不再解释。对于 net_cls.classid 文件,我们一般 echo 的是一个 0xAAAABBBB 的值, AAAA 对应 class 中:前面的数字,而 BBBB 对应后面的数字,如: 0x00010100 就表示这个组的数据包将被分类到 1:100 中,限速为 30mbit ,以此类推。之后我们把 http 服务放倒 jerry 组中看看效果:
[root@localhost Desktop]# for i in `ps ax|grep httpd|awk '{ print $1}'`;do echo $i > /sys/fs/cgroup/net_cls/jerry/tasks;done
bash: echo: write error: No such process
[root@localhost Desktop]# cat /sys/fs/cgroup/net_cls/jerry/tasks
75733
75734
75735
75736
75737
75738
75777
75778
75779
测试效果:
zorrozou-nb:~ zorro$ curl -O http://192.168.139.136/file
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 1024M 0 5118k 0 0 1162k 0 0:15:01 0:00:04 0:14:57 1162k
确实限速在了 10mbitps 。成功达到效果,再来看看放倒 zorro 组下:
[root@localhost Desktop]# for i in `ps ax|grep httpd|awk '{ print $1}'`;do echo $i > /sys/fs/cgroup/net_cls/zorro/tasks;done
bash: echo: write error: No such process
[root@localhost Desktop]# cat /sys/fs/cgroup/net_cls/zorro/tasks
75733
75734
75735
75736
75737
75738
75777
75778
75779
再次测试效果:
zorrozou-nb:~ zorro$ curl -O http://192.168.139.136/file
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 1024M 0 5586k 0 0 2334k 0 0:07:29 0:00:02 0:07:27 2334k
限速 20mbps 成功。如果想要修改对于一个分类的限速,使用如下命令即可:
tc cl change dev eno16777736 parent 1: classid 1:100 htb rate 100mbit
关于命令参数的详细解释,这里不做过多说明了。大家可以自行找帮助。
最后
终于,我的 Cgroup 系列四部曲算是告一段落了。实际上 Linux 的 Cgroup 除了 CPU 、内存、 IO 和网络的资源管理以外,还有一些其它的配置,比如针对设备文件的访问控制和 freezer 机制等功能,但是这些功能都相对比较简单,个人认为没必要过多介绍了,大家要用的时候自己找帮助即可。
最后的最后,还是奉送一张 Linux 网络相关的数据包处理流程图,从这张图上大家可以清晰的看到 qdisc 的作用位置和其根 iptables 的作用关系。原图链接在此。

 |
1
matrix67 2016-02-05 12:41:25 +08:00 via Android
囧,网络一直是短板啊,看不懂。
|
|
2
matrix67 2016-02-05 12:41:49 +08:00 via Android
过年好好学学 openvswitch
|
 |
3
yylyyl 2016-02-05 13:59:36 +08:00 via iPhone
活捉校长一只!
|
 |
4
ioiioi 2016-02-05 15:15:33 +08:00
赞一个!
我最近正在研究 codel 和 fq_codel ,你的文章真是及时雨。在中文社区可以算是第一人的吧,至少现在还没有看到第二 |
 |
5
jerry017cn OP :P @yylyyl 那么你是?
|
|
6
jerry017cn OP @ioiioi 嘿嘿,过奖过奖,应该很多大牛都懂,人家就是没时间发文章而已。
|
 |
7
Admstor 2016-02-05 22:15:08 +08:00
过年放假,正好把楼主系列文章拜读一下
|
 |
8
kslr 2016-02-10 19:06:22 +08:00 via Android
很棒
|