推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 144 天前的主题,其中的信息可能已经有所发展或是发生改变。
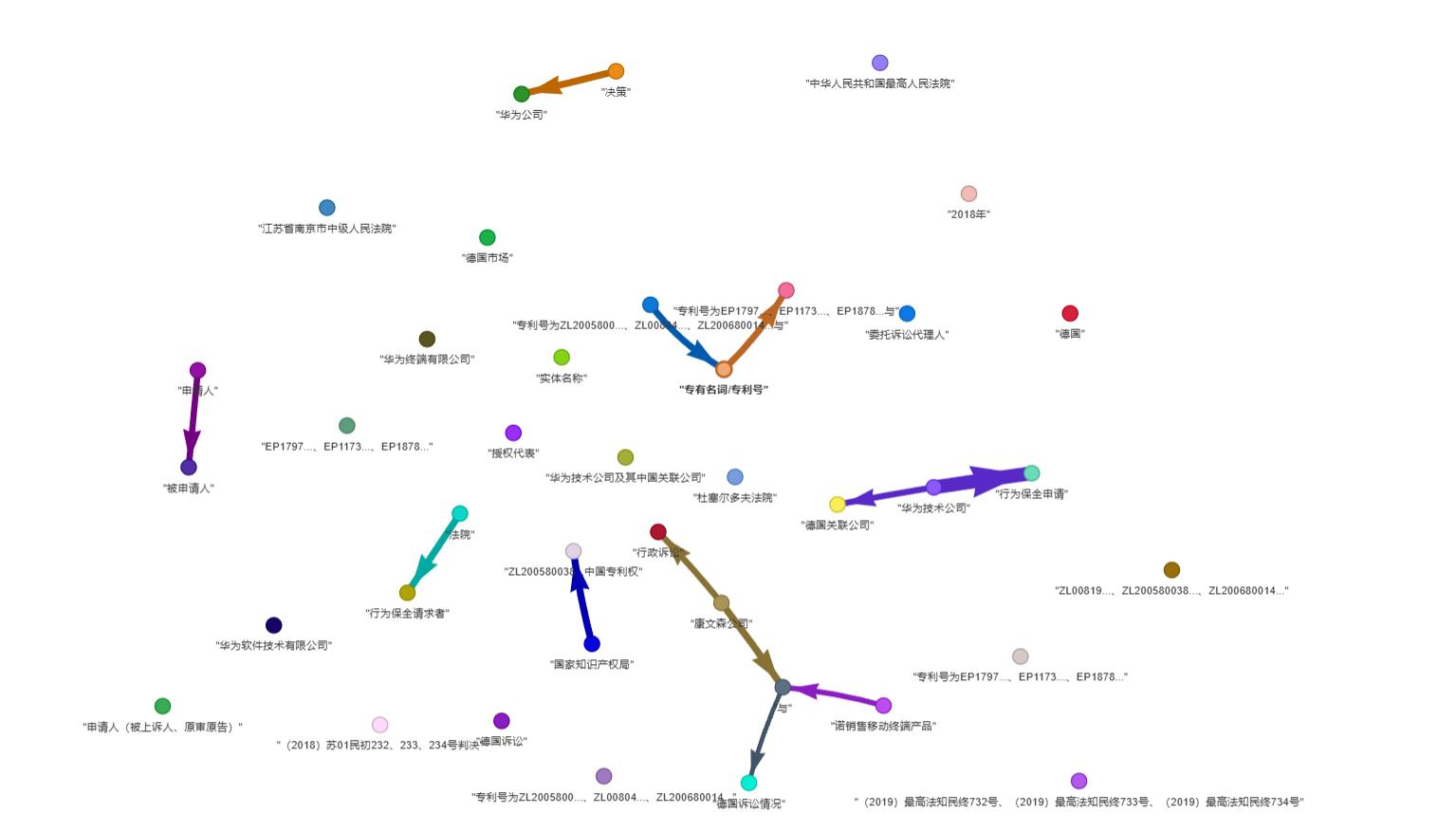
试了下LightRAG 本地化 rag 中的翘楚,效果非常不错,搭配 ollama 。
如图随便找个文档,示例是从裁判文书下载的文档
快速上手的话直接 pip 安装即可:
pip install lightrag-hku
注意事项
- llm_model_max_token_size 配置
32768后,服务端 ollama 的OLLAMA_NUM_PARALLEL并发数就不要配置了,如果配置则这个参数乘以对应的数值就会显存爆炸 - 其次 图谱生成的配置中并不是完成本地化的,对应的图谱 js 的 cdn 是外面的
ollama demo
import os
import logging
from lightrag import LightRAG, QueryParam
from lightrag.llm import ollama_model_complete, ollama_embedding
from lightrag.utils import EmbeddingFunc
# 设置日志级别
logging.basicConfig(format="%(levelname)s:%(message)s", level=logging.INFO)
# 创建工作目录
WORKING_DIR = "./my_rag_project"
os.makedirs(WORKING_DIR, exist_ok=True)
# 初始化 LightRAG,使用 Ollama 模型
rag = LightRAG(
working_dir=WORKING_DIR,
llm_model_func=ollama_model_complete,
llm_model_name="qwen2:7b", # 使用 qwen 模型
llm_model_max_async=4, # 最大并发请求数
llm_model_max_token_size=32768,
llm_model_kwargs={
"host": "http://localhost:11434", # Ollama 服务地址
"options": {"num_ctx": 32768} # 上下文窗口大小
},
embedding_func=EmbeddingFunc(
embedding_dim=768,
max_token_size=8192,
func=lambda texts: ollama_embedding(
texts,
embed_model="nomic-embed-text", # 使用 nomic-embed-text 作为嵌入模型
host="http://localhost:11434"
),
),
)
# 插入文档并进行查询
documents = [
"人工智能(AI)是计算机科学的一个分支,致力于开发能模拟人类智能的系统。",
"机器学习是 AI 的核心技术之一,它使计算机能够从数中学习和改进。",
"深度学习是机器学习的一个子领域,使用多层神经网络处理复杂问题。"
]
# 插入文档
rag.insert(documents)
# 使用不同的检索模式进行查询
modes = ["naive", "local", "global", "hybrid"]
query = "请解释 AI 、机器学习和深度学习之间的关系"
for mode in modes:
print(f"\n 使用{mode}模式的查询结果:")
result = rag.query(query, param=QueryParam(mode=mode))
print(result)
全文内容
 |
1
mdb 144 天前
问下大佬,LightRAG 对聊天记录之类的数据支持怎么样,比如我想把所有的聊天记录扔给它,然后让它总结这几年的话题,不知道能不能实现
|
 |
2
suke119 OP 要改下提示词,prompt py 里面 按照聊天记录需要总结提取的修改下
|
 |
4
mcgill 144 天前
m1 的 macmini 跑个 ollama 的本地真是等死我了。
|
|
5
mdb 140 天前
我本地试了下,用了阿西莫夫的最后的问题这篇文章做测试,结果感觉词提取不出来,一到最后问问题的时候就会报错:cannot unpack non-iterable NoneType object
INFO:lightrag:Logger initialized for working directory: ./dickens INFO:lightrag:Load KV llm_response_cache with 20 data INFO:lightrag:Load KV full_docs with 0 data INFO:lightrag:Load KV text_chunks with 0 data INFO:lightrag:Loaded graph from ./dickens\graph_chunk_entity_relation.graphml with 0 nodes, 0 edges INFO:nano-vectordb:Load (0, 768) data INFO:nano-vectordb:Init {'embedding_dim': 768, 'metric': 'cosine', 'storage_file': './dickens\\vdb_entities.json'} 0 data INFO:nano-vectordb:Load (0, 768) data INFO:nano-vectordb:Init {'embedding_dim': 768, 'metric': 'cosine', 'storage_file': './dickens\\vdb_relationships.json'} 0 data INFO:nano-vectordb:Load (9, 768) data INFO:nano-vectordb:Init {'embedding_dim': 768, 'metric': 'cosine', 'storage_file': './dickens\\vdb_chunks.json'} 9 data INFO:httpx:HTTP Request: POST http://localhost:11434/api/chat "HTTP/1.1 200 OK" INFO:lightrag:kw_prompt result: { "high_level_keywords": ["人物", "故事"], "low_level_keywords": ["主人公"] } INFO:httpx:HTTP Request: POST http://localhost:11434/api/embeddings "HTTP/1.1 200 OK" Traceback (most recent call last): File "D:\download\ff\LightRAG-main\examples\lightrag_ollama_demo.py", line 40, in <module> rag.query("这故事的主人公是谁?", param=QueryParam(mode="local")) File "D:\download\ff\LightRAG-main\lightrag\lightrag.py", line 427, in query return loop.run_until_complete(self.aquery(query, param)) File "E:\Python310\lib\asyncio\base_events.py", line 649, in run_until_complete return future.result() File "D:\download\ff\LightRAG-main\lightrag\lightrag.py", line 431, in aquery response = await kg_query( File "D:\download\ff\LightRAG-main\lightrag\operate.py", line 494, in kg_query context = await _build_query_context( File "D:\download\ff\LightRAG-main\lightrag\operate.py", line 552, in _build_query_context ( TypeError: cannot unpack non-iterable NoneType object |