
这是一个创建于 653 天前的主题,其中的信息可能已经有所发展或是发生改变。
在 Google SRE 的著作《 Google 运维解密》(原作名:Site Reliability Engineering: How Google Runs Production Systems)中,Google SRE 的关键成员们不惜在三个章节的篇幅中不同程度描述在 Google 他们是如何 on-call 的。
Google SRE 实践中,有一个广为人知的理念:减少琐事,用软件工程的方式解决运维问题。具体到实际操作层面,Google SRE 设定了一个重要的、公开的目标:保持每个 SRE 的工作时间中琐事比例低于 50%,SRE 至少花 50% 的时间在工程项目上,以减少未来的琐事或为服务增加新功能。
Google SRE 团队认为,琐事过多,会产生以下不利的后果:
- 职业停滞:如果花在工程项目上的时间太少,你的职业发展会变慢,甚至停滞。Google 确实会奖励做那些脏活累活的人,但是仅仅是该工作是不可避免,并有巨大的正面影响的时候才会这样做。没有人可以通过不停地做脏活累活满足自己的职业发展。
- 士气低落:每个人对自己可以承担的琐事限度有所不同,但是一定有个限度。过多的琐事会导致过度劳累、厌倦和不满。
- 造成误解:我们努力确保每个 SRE 以及每个与 SRE 一起工作的人都理解 SRE 是一个工程组织。如果个人或者团队过度参与琐事,会破坏这种角色,造成误解。
- 进展缓慢:琐事过多会导致团队生产力下降。如果 SRE 团队忙于为手工操作和导出数据救火,新功能的发布就会变慢。
- 开创先河:如果 SRE 过于愿意承担琐事,研发同事就更倾向于加入更多的琐事,有时候甚至将本来应该由研发团队承担的运维工作转给 SRE 来承担。其他团队也会开始指望 SRE 接受这样的工作,这显然是不好的。
- 促进摩擦产生:即使你个人对琐事没有怨言,你现在的或未来的队友可能会很不开心。如果团队中引入了太多的琐事,其实就是在鼓励团队里最好的工程师开始寻找其他地方提供的更有价值的工作。
- 违反承诺:那些为了项目工程工作而新入职的员工,以及转入 SRE 的老员工会有被欺骗的感觉,这非常不利于公司的士气。
根据统计数据显示,琐事的第一大来源是中断性工作,另一个主要来源是on-call。前者大多为与服务相关的非紧急事务,后者则为紧急的应急事务。在 Google ,一个 SRE 团队至少要保持6~8 人的规模,才能保证因 on-call 轮值产生的琐事低于 30%。
管中窥豹,Google SRE 的工作方式,不是谁都有条件学,也不是谁都可以学的来的。需要从文化 机制 工具层面综合考虑,以国内的运维现状来看,这是有一些实际困难和阻力的。
文化
首先,在文化层面,Google SRE 倡导以人为本,关注人的发展,着眼长期结果。在国内加班文化盛行,996 甚嚣尘上。具体到 IT 运维领域,表现为:
技术人员工作和生活很难平衡,上班与下班没有明确界限,最终变成了只有值班,没有轮换,7x24 小时响应。工作规划以短期目标驱动,缺乏长期主义,导致技术人员每天忙于“战术性”的工作,琐事缠身,而无暇通过软件工程的手段一劳永逸的解决长期问题,久而久之堆积为技术债务。35 岁 IT 打工人困境较为普遍。归根结底,是人的发展,没有得到足够的重视,由于不断的有大量新人进入到 IT 行业,使得很多企业选择了不断“汰换人”而非“发展人”这样的路线,自然也就无从谈起“费力减少琐事”了。
机制
其次,在机制层面,Google SRE 明确执行“琐事不能超过 50%”的机制,确保一个独立的 SRE team 最少保持 6 人的规模,以支撑轮换 on-call ,同时给予工作时间之外的 on-call 工作以额外的补贴。
在国内这个操作难度很大,国内的大多数企业,SRE 人数 vs 研发总人数的比例普遍接近 1:100 ,要保持 6 人的 SRE team ,几乎是不可能的。
工具
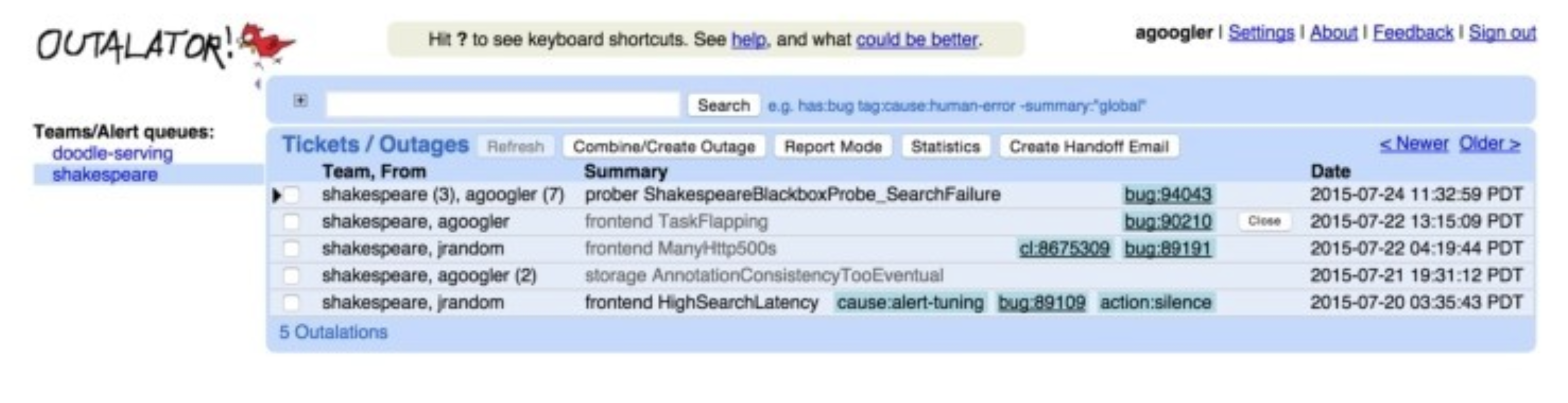
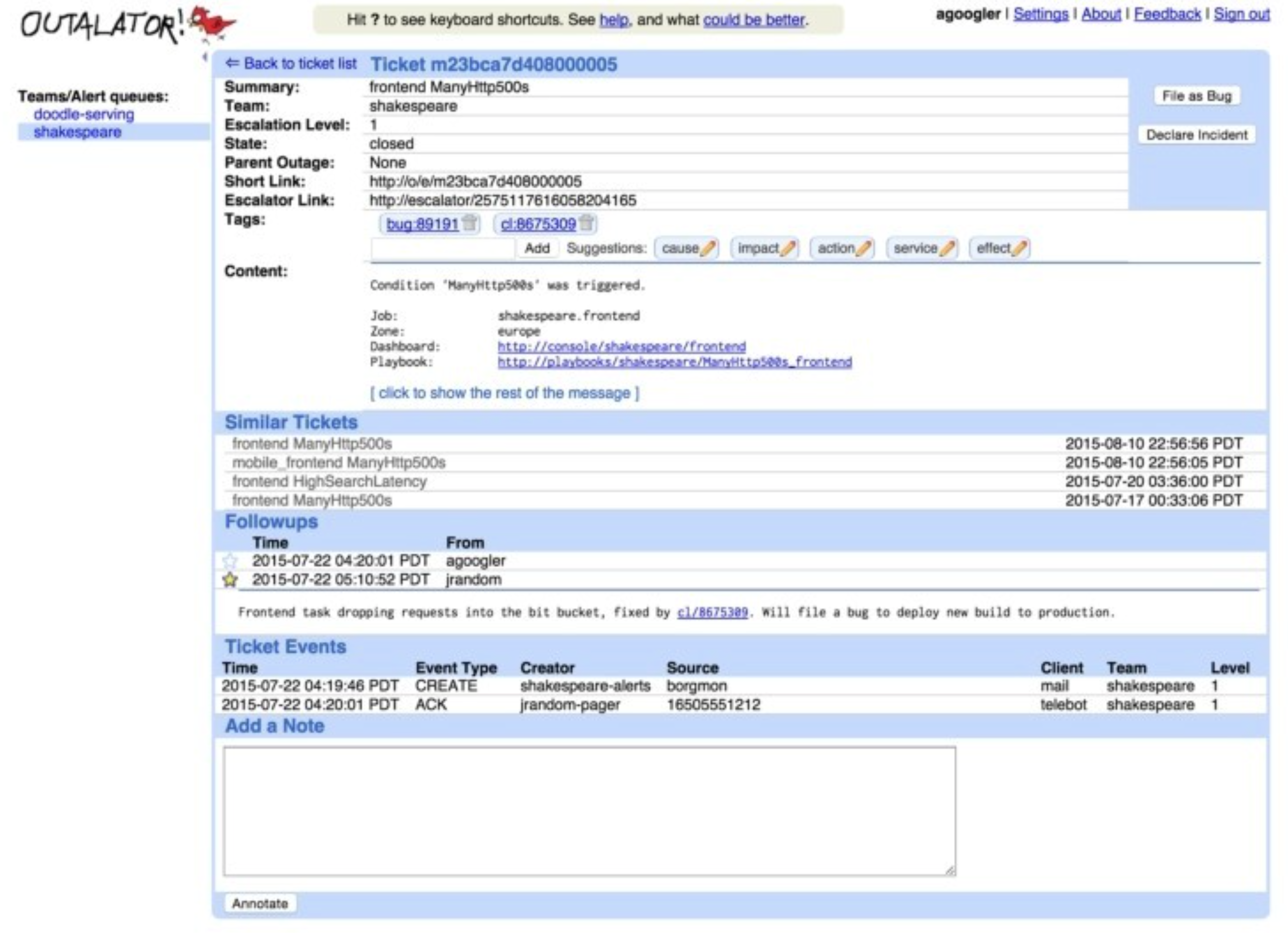
最后,在工具层面,Google SRE 内部使用的 on-call 工具为 Outalator 。在 Outalator 中,SRE 们在一个集中的平台上,管理着告警的全生命周期过程,具体的来讲,功能包括:
告警聚合:将多个告警信息“聚合”成一个单独的故障,SRE 以“故障”为维度来跟进和处理,大大降低了告警的发送量,避免重复性工作,降低了告警中的噪音,提高处理效率,以及减少工作失误。
加标签:给不同的故障,加上标签,用来额外描述故障的信息,方便 SRE 以标签为维度来筛选、统计、分析,提高告警处理效率。
提供告警数据分析能力:从不同的维度,比如团队、个人、服务、机房等不同的维度,分析告警的数量变化趋势、告警的响应效率、处理效率,以便 SRE 能从宏观层面分析 on-call 工作的不足之处,并有针对性的加以改进。
一键生成报告和公告:Outalator 中对一线 SRE 更有用的功能是可以选择一系列故障,将它们的标题、标签和“重要的”记录信息用邮件格式发送给下一个 on-call 工程师(也可以 CC 其他人或邮件列表)。这样可以很容易地进行交接工作。Outalator 同时支持一种“报告模式”,为周期性的生产服务评审(大部分团队每周进行一次)提供帮助。
Outalator 大概长下面这样:
总结来讲,通过使用专业的 on-call 工具,可以有效的解决日常工作中运维和研发人员面临的以下困扰:
- 技术团队每天接收到大量的告警。
- 很多告警长时间无响应,长期无人问津。
- 告警与告警之间缺乏关联性,处理效率低下。
- 告警处理缺乏协同,处理过程不透明,信息难以共享,知识难以沉淀。
- 很多告警并未准确反应实际情况,无谓的消耗技术团队精力。
- 客户/用户往往先于技术团队发现故障,客户满意度持续走低。
- 无法量化的衡量应急响应的现状和效率,无法制定出改进和优化路线。
我们可以像 Google SRE 一样 on-call 吗?
通过以上的分析,坏消息是文化和机制层面,学起来有阻力,好消息是工具层面,Google 的 on-call 工具可选项还不少。下面两款 on-call 工具推荐给大家:
 |
1
levelworm 2024-02-27 10:48:02 +08:00 via Android
的确很有意思,可惜找不到这种工作。
|
 |
2
txj 2024-02-27 10:57:50 +08:00
营销内容,来总
|
 |
3
diagnostics 2024-02-27 11:28:26 +08:00
文章还可以,虽然后面是推广
|
 |
4
clifftts 2024-02-27 18:36:51 +08:00
之前公司也想搞 sre ,各个组抽人轮流跟运维一起 oncall,负责业务及异常排除定位,顺带做一些规范落地,问题整改啥的,搞这个比开发紧张多了,尤其是在没有很好的排查工具的时候,还考验业务能力
|
|
8
clifftts 2024-02-28 16:57:48 +08:00
@laiwei 这个确实是,尤其是微服务的架构中,找日志,复现场景,协调其他组沟通定位,快速给出解决方案,还有各组频繁发布带来的新问题,还要修复数据,很辛苦。oncall 和迭代开发完全是两个节奏。
|
|
9
levelworm 2024-02-28 21:26:52 +08:00 via Android
感觉最好玩的还是写开发者工具。
|
 |
10
nullyouraise 2024-02-29 09:46:50 +08:00
国内很多大厂的 on-call 都是服务器报警就自动给人打电话,打不通就一直打,我在字节和蚂蚁的同学都疯狂吐槽,凌晨 1 点打电话叫起来看日志,活分给谁就谁来看,根本没有什么协同可言
|
 |
11
laiwei OP @nullyouraise 如果是关键服务受损,确实是需要第一时间处理的。只不过是需要考虑定期的轮换,否则压力太大,涉及到轮换,就需要有合适的协同工具。
|
 |
12
yuepu 2024-02-29 18:08:18 +08:00
@nullyouraise 是的,打不通就往上升级,一直会升级到 CEO 那里
|